Dragon Arrow written by Tatsuya Nakaji, all rights reserved 
updated on 2019-08-18

問 1:太郎くんはスーパーで 1 個 100 円のリンゴを 2 個買いました。支払う金額 を求めなさい。ただし、消費税が 10% 適用されるものとします。
計算グラフで解くと...

乗算レイヤーを2回使って220円という出力が計算されます。
問 2:太郎くんはスーパーでリンゴを 2 個、みかんを 3 個買いました。リンゴは1 個 100 円、みかんは 1 個 150 円です。消費税が 10% かかるものとして、支払う金額を求めなさい。
計算グラフで解くと...

乗算レイヤーを3回、加算レイヤーを1回使って715円という出力が計算されます。
計算グラフを使って問題を解くには、
1. 計算グラフを構築する
2. 計算グラフ上で計算を左から右へ進める
という流れで行います。ここで 2 番目の「計算を左から右へ進める」というステップは、順方向の伝播、略して、順伝播(forward propagation)
右から左方向への伝播を逆伝播(backward propagation)
計算グラフを使う最大の理由は、逆方向の伝播に よって「微分」を効率良く計算できる点
最終的に L という値を出力する大きな計算グラフを想定

逆伝播の計算は以下のようになっている
①では、x -> z になっているので波の強度は (dz / dx) と考える。
上流から流れてきた値(=dL/dz)が 強度 (dz / dx)の波で強められるので、(上流値)×(波の強度)で下流値が出る
②では、y -> z になっているので波の強度は (dz / dy) と考える。
上流から流れてきた値(=dL/dz)が 強度 (dz / dy)の波で強められるので、(上流値)×(波の強度)で下流値が出る


入力値が1アップした時の出力値のアップ
りんごの値段が1円アップ -> 全支払いが2.2円アップ
支払いのリンゴの値段の微分は 2.2
みかんの値段が1円アップ -> 全支払いが3.3円アップ
支払いのみかんの値段の微分は 2.2
消費税が1(100%)アップ -> 全支払いが650円アップ
支払いの消費税の値段の微分は 650
「微分」を効率良く計算できる
筆者の逆伝播の考え方
渓流がたくさんあります。
流れの強さは、緩やかなものもあれば急なものもあり、流れの向きは順速(加速する)のものもあれば逆速(減速する)のものもあります。
上流から岩石を下流に向けて流すと、全ての滝を超えて下流についた頃には隕石のスピードになったとします。
次に、全ての滝に関して、流れの勢いは変えないまま、流れの向きだけを反対にします。 そして今度は下流から上流に岩石を流したとします。
全ての滝を超えて上流についた頃には同じく隕石のスピードになっています。
これが逆伝播の理屈です。
順伝播と逆伝播の違いは、渓流を上流から下流に向かうか、下流から上流に向かうかのみの違いで、 準速の渓流は準速のまま、逆速の渓流は逆速のまま計算しているため、 結局、岩石が渓流を渡る順番が違うだけなのです。
したがって、順伝播も逆伝播も計算結果は同じで、どちらの方法でも岩石は同じスピードで帰ってくる。
ソースコードは ch05/layer_naive.py
class MulLayer:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y # xとyを逆にする
dy = dout * self.x
return dx, dy
上記の順伝播は次のように実装することができます ソースコードは ch05/buy_apple.py
from layer_naive import * apple = 100 apple_num = 2 tax = 1.1 mul_apple_layer = MulLayer() mul_tax_layer = MulLayer() # forward apple_price = mul_apple_layer.forward(apple, apple_num) price = mul_tax_layer.forward(apple_price, tax) # backward dprice = 1 dapple_price, dtax = mul_tax_layer.backward(dprice) dapple, dapple_num = mul_apple_layer.backward(dapple_price) print("price:", int(price)) print("dApple:", dapple) print("dApple_num:", int(dapple_num)) print("dTax:", dtax) # price: 220 # dApple: 2.2 # dApple_num: 110 # dTax: 200
ソースコードは ch05/layer_naive.py
class AddLayer:
def __init__(self):
pass # クラス変数としてx,yを保持する必要がない 「何も行わない」という命令
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1 # 下流に流すだけ
dy = dout * 1
return dx, dy
計算グラフは、Python で実装すると次のようになります(ソースコードは ch05/buy_apple_orange.py )
from layer_naive import * apple = 100 apple_num = 2 orange = 150 orange_num = 3 tax = 1.1 # layer mul_apple_layer = MulLayer() mul_orange_layer = MulLayer() add_apple_orange_layer = AddLayer() mul_tax_layer = MulLayer() # forward apple_price = mul_apple_layer.forward(apple, apple_num) # (1) orange_price = mul_orange_layer.forward(orange, orange_num) # (2) all_price = add_apple_orange_layer.forward(apple_price, orange_price) # (3) price = mul_tax_layer.forward(all_price, tax) # (4) # backward dprice = 1 dall_price, dtax = mul_tax_layer.backward(dprice) # (4) dapple_price, dorange_price = add_apple_orange_layer.backward(dall_price) # (3) dorange, dorange_num = mul_orange_layer.backward(dorange_price) # (2) dapple, dapple_num = mul_apple_layer.backward(dapple_price) # (1) print("price:", int(price)) print("dApple:", dapple) print("dApple_num:", int(dapple_num)) print("dOrange:", dorange) print("dOrange_num:", int(dorange_num)) print("dTax:", dtax) # price: 715 # dApple: 2.2 # dApple_num: 110 # dOrange: 3.3000000000000003 # dOrange_num: 165 # dTax: 650
| y = | x (x>0) |
| 0 (x≦0) |
| ∂y/∂x = | 1 (x>0) |
| 0 (x≦0) |
ReLU レイヤの実装は、common/layers.py

class Relu: def __init__(self): self.mask = None def forward(self, x): self.mask = (x <= 0) # x=np.array([ 1.29400019, -0.78059715, -1.09235197)] の時、mask=np.array([False, True, True]) out = x.copy() # 参照コピーではなく値コピー out[self.mask] = 0 # out=np.array([ 1.29400019, 0., 0.)] Trueのインデックスに代入が適用される return out def backward(self, dout): dout[self.mask] = 0 # xが0以下の時は0を流す、それ以外は値をそのまま流す dx = dout return dx
シグモイド関数
y=1 / (1 + exp(−x))

Sigmoid レイヤを Python で実装(common/layers.py)
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dxAffine レイヤの計算グラフ
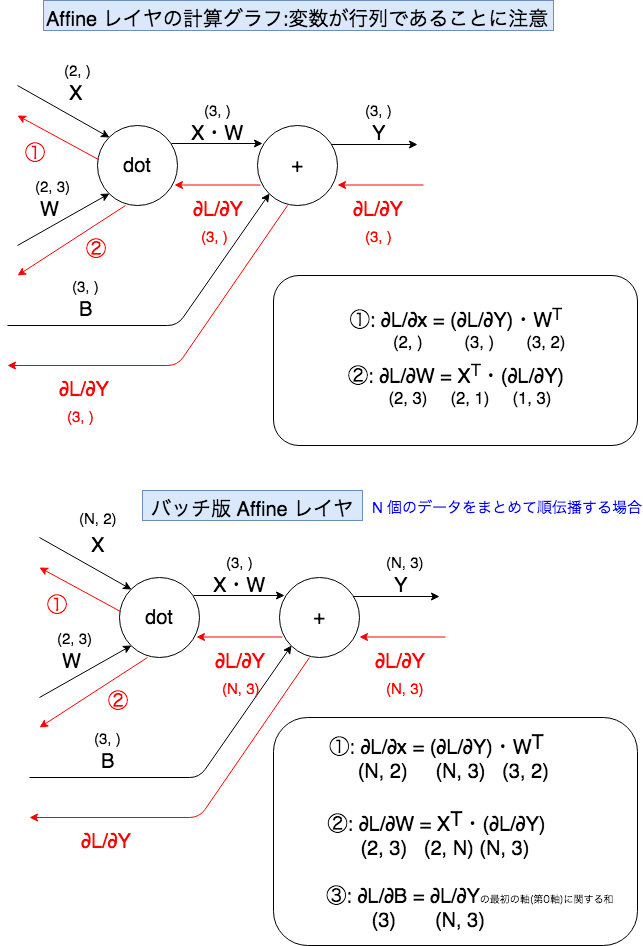
Affine の実装(common/layers.py)
class Affine:
def __init__(self, W, b):
self.W =W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dxSoftmax レイヤは、入力された値を正規化(出力の和が1 になるように変形)して出力
なお、手書き数字認識は、10 クラス分類を 行うため、Softmax レイヤへの入力は 10 個
Softmax レイヤの出力

損失関数である交差 エントロピー誤差(cross entropy error)も含めて、「Softmax-with-Loss レイヤ」 という名前のレイヤで実装
Softmax-with-Loss レイヤ(ソ フトマックス関数と交差エントロピー誤差)の計算グラフ

逆伝播の結果を見ると、Softmax レイヤからの逆伝播は、(y1 − t1, y2 − t2, y3 − t3) という“キレイ”な結果になっています
(y1, y2, y3) はSoftmax レイヤの出力、(t1, t2, t3) は教師データなので、(y1 − t1, y2 − t2, y3 − t3)は、Softmax レイヤの出力と教師ラベルの差分
「ソフトマックス関数」の損失関数として「交差エントロピー誤差」を用いると、 逆伝播が (y1 − t1, y2 − t2, y3 − t3) という“キレイ”な結果になりました。 実は、そのような“キレイ”な結果は偶然ではなく、そうなるように交差エント ロピー誤差という関数が設計された。
また、回帰問題では出力層に「恒 等関数」を用い、損失関数として「2 乗和誤差」を用いますが(「3.5 出力層の 設計」参照)、これも同様の理由によります。つまり、「恒等関数」の損失関数 として「2 乗和誤差」を用いると、逆伝播が (y1 − t1, y2 − t2, y3 − t3) とい う“キレイ”な結果になる。
Softmax-with-Loss レイヤの実装(common/layers.py)
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmaxの出力
self.t = None # 教師データ(one-hot vector)
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx逆伝播の際には、伝播する値をバッチの個数(batch_size)で割ることで、データ 1 個あたりの 誤差が前レイヤへ伝播する点に注意
2 層のニューラルネットワークをTwoLayerNet として実装
(ch05/two_layer_net.py) import sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 import numpy as np from common.layers import * from common.gradient import numerical_gradient from collections import OrderedDict class TwoLayerNet: def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01): # 重みの初期化 self.params = {} self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size) self.params['b1'] = np.zeros(hidden_size) self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size) self.params['b2'] = np.zeros(output_size) # レイヤの生成 self.layers = OrderedDict() self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1']) self.layers['Relu1'] = Relu() self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2']) self.lastLayer = SoftmaxWithLoss() def predict(self, x): # インスタンスを取り出して順伝播させる for layer in self.layers.values(): x = layer.forward(x) return x # x:入力データ, t:教師データ def loss(self, x, t): y = self.predict(x) return self.lastLayer.forward(y, t) def accuracy(self, x, t): y = self.predict(x) y = np.argmax(y, axis=1) if t.ndim != 1 : t = np.argmax(t, axis=1) accuracy = np.sum(y == t) / float(x.shape[0]) return accuracy # x:入力データ, t:教師データ def numerical_gradient(self, x, t): loss_W = lambda W: self.loss(x, t) grads = {} grads['W1'] = numerical_gradient(loss_W, self.params['W1']) grads['b1'] = numerical_gradient(loss_W, self.params['b1']) grads['W2'] = numerical_gradient(loss_W, self.params['W2']) grads['b2'] = numerical_gradient(loss_W, self.params['b2']) return grads def gradient(self, x, t): # forward self.loss(x, t) # backward dout = 1 dout = self.lastLayer.backward(dout) layers = list(self.layers.values()) # 各層のインスタンスをリストで取得 layers.reverse() # 下流から上流の順にする for layer in layers: dout = layer.backward(dout) # 設定 grads = {} grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db return grads
OrderedDictは順番付きディクショナリ
キーには層の名前を、値には層の初期化したインスタンスがはいる
これからは、計算に時間のかかる数値微分ではなく、誤差逆伝播法によって勾配を求める
数値微分で勾配を求めた結果と、誤差逆伝播法で求めた勾配の結果が一致すること――正確には、ほとんど 近い値にあること――を確認する作業を勾配確認という。
勾配確認の実装(ch05/gradient_check.py)
import sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 import numpy as np from dataset.mnist import load_mnist from two_layer_net import TwoLayerNet # データの読み込み (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True) network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10) x_batch = x_train[:3] t_batch = t_train[:3] grad_numerical = network.numerical_gradient(x_batch, t_batch) grad_backprop = network.gradient(x_batch, t_batch) for key in grad_numerical.keys(): diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) ) print(key + ":" + str(diff))
$ python gradient_check.py
W1:4.3856368115776307e-10
b1:2.5851454858716577e-09
W2:5.371920504880761e-09
b2:1.3970113447031584e-07
この結果から、数値微分と誤差逆伝播法でそれぞれ求めた勾配の差はかなり小さいことが分かる
コンピュータの計算は有限の精度で行われるため、誤差は通常 0 にはならない
誤差逆伝播法で勾配を求める
(ch05/train_nueralnet.py)
import sys, os sys.path.append(os.pardir) import numpy as np from dataset.mnist import load_mnist from two_layer_net import TwoLayerNet # データの読み込み (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True) network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10) iters_num = 10000 train_size = x_train.shape[0] batch_size = 100 learning_rate = 0.1 train_loss_list = [] train_acc_list = [] test_acc_list = [] iter_per_epoch = max(train_size / batch_size, 1) for i in range(iters_num): batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # 勾配誤差逆伝播法によって勾配を求める #grad = network.numerical_gradient(x_batch, t_batch) grad = network.gradient(x_batch, t_batch) # 更新 for key in ('W1', 'b1', 'W2', 'b2'): network.params[key] -= learning_rate * grad[key] loss = network.loss(x_batch, t_batch) train_loss_list.append(loss) if i % iter_per_epoch == 0: train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) print(train_acc, test_acc)
ニューラルネットワークの構成要素をレイヤとして実装することで、勾配の計算を効率的に求めることができる(誤差逆伝播法)。
数値微分と誤差逆伝播法の結果を比較することで、誤差逆伝播法の実装に誤りがないことを確認できる(勾配確認)。