Dragon Arrow written by Tatsuya Nakaji, all rights reserved 
updated on 2019-08-20

CNNのネットワークを深くしたものをVGGという

(ch08/deep_convnet.py)
# coding: utf-8 import sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 import pickle import numpy as np from collections import OrderedDict from common.layers import * class DeepConvNet: """認識率99%以上の高精度なConvNet ネットワーク構成は下記の通り conv - relu - conv- relu - pool - conv - relu - conv- relu - pool - conv - relu - conv- relu - pool - affine - relu - dropout - affine - dropout - softmax """ def __init__(self, input_dim=(1, 28, 28), conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1}, conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1}, conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1}, hidden_size=50, output_size=10): # 重みの初期化=========== # 各層のニューロンひとつあたりが、前層のニューロンといくつのつながりがあるか(TODO:自動で計算する) pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size]) weight_init_scales = np.sqrt(2.0 / pre_node_nums) # ReLUを使う場合に推奨される初期値 self.params = {} pre_channel_num = input_dim[0] for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]): self.params['W' + str(idx+1)] = weight_init_scales[idx] * np.random.randn(conv_param['filter_num'], pre_channel_num, conv_param['filter_size'], conv_param['filter_size']) self.params['b' + str(idx+1)] = np.zeros(conv_param['filter_num']) pre_channel_num = conv_param['filter_num'] self.params['W7'] = weight_init_scales[6] * np.random.randn(64*4*4, hidden_size) self.params['b7'] = np.zeros(hidden_size) self.params['W8'] = weight_init_scales[7] * np.random.randn(hidden_size, output_size) self.params['b8'] = np.zeros(output_size) # レイヤの生成=========== self.layers = [] self.layers.append(Convolution(self.params['W1'], self.params['b1'], conv_param_1['stride'], conv_param_1['pad'])) self.layers.append(Relu()) self.layers.append(Convolution(self.params['W2'], self.params['b2'], conv_param_2['stride'], conv_param_2['pad'])) self.layers.append(Relu()) self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2)) self.layers.append(Convolution(self.params['W3'], self.params['b3'], conv_param_3['stride'], conv_param_3['pad'])) self.layers.append(Relu()) self.layers.append(Convolution(self.params['W4'], self.params['b4'], conv_param_4['stride'], conv_param_4['pad'])) self.layers.append(Relu()) self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2)) self.layers.append(Convolution(self.params['W5'], self.params['b5'], conv_param_5['stride'], conv_param_5['pad'])) self.layers.append(Relu()) self.layers.append(Convolution(self.params['W6'], self.params['b6'], conv_param_6['stride'], conv_param_6['pad'])) self.layers.append(Relu()) self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2)) self.layers.append(Affine(self.params['W7'], self.params['b7'])) self.layers.append(Relu()) self.layers.append(Dropout(0.5)) self.layers.append(Affine(self.params['W8'], self.params['b8'])) self.layers.append(Dropout(0.5)) self.last_layer = SoftmaxWithLoss() def predict(self, x, train_flg=False): for layer in self.layers: if isinstance(layer, Dropout): x = layer.forward(x, train_flg) else: x = layer.forward(x) return x def loss(self, x, t): y = self.predict(x, train_flg=True) return self.last_layer.forward(y, t) def accuracy(self, x, t, batch_size=100): if t.ndim != 1 : t = np.argmax(t, axis=1) acc = 0.0 for i in range(int(x.shape[0] / batch_size)): tx = x[i*batch_size:(i+1)*batch_size] tt = t[i*batch_size:(i+1)*batch_size] y = self.predict(tx, train_flg=False) y = np.argmax(y, axis=1) acc += np.sum(y == tt) return acc / x.shape[0] def gradient(self, x, t): # forward self.loss(x, t) # backward dout = 1 dout = self.last_layer.backward(dout) tmp_layers = self.layers.copy() tmp_layers.reverse() for layer in tmp_layers: dout = layer.backward(dout) # 設定 grads = {} for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)): grads['W' + str(i+1)] = self.layers[layer_idx].dW grads['b' + str(i+1)] = self.layers[layer_idx].db return grads def save_params(self, file_name="params.pkl"): params = {} for key, val in self.params.items(): params[key] = val with open(file_name, 'wb') as f: pickle.dump(params, f) def load_params(self, file_name="params.pkl"): with open(file_name, 'rb') as f: params = pickle.load(f) for key, val in params.items(): self.params[key] = val for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)): self.layers[layer_idx].W = self.params['W' + str(i+1)] self.layers[layer_idx].b = self.params['b' + str(i+1)]
(ch08/train_deepnet.py)
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from deep_convnet import DeepConvNet
from common.trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
network = DeepConvNet()
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr':0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
# パラメータの保存
network.save_params("deep_convnet_params.pkl")
print("Saved Network Parameters!") Data Augmentaion の例
Data Augmentaion の例
Data Augmentaionは、上記の移動や回転の他にも、画像の中から一部を切り出す「crop 処理」や、 左右をひっくり返す「flip 処理」など様々な方法で拡張できる。
* flip 処理は、画像の対称性を考慮する必要のない場合にのみ有効です。
層を深くすることの重要性について、理論的に多くのことはわからない
2012 年に開催された大規模画像認識のコンペティション ILSVRC(ImageNet Large Scale Visual Recognition Challenge)で、ディープラーニングによる手法――通称、AlexNet――が、圧倒的な成績 で優勝し、これまでの画像認識に対するアプローチを根底から覆した。まさに、 転換点となった 2012 年のディープラーニングの逆襲により、それ以降のコンペティ ションでは、常にディープラーニングが主役に躍り出た。
本節ではIVSVRCを軸に、最近のディープラーニングのトレーニングをみる
100 万枚を超える画像のデータセットです。さまざまな種類の画像が含まれており、それぞれの画像にはラベル(クラス名) が紐付けられています。この巨大なデータセットを使って、ILSVRC という画像認識のコンペティションが毎年行われる

以下文献より引用 J. Deng, W. Dong, R. Socher, L.J. Li, Kai Li, and Li Fei-Fei (2009):ImageNet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, 2009. CVPR 2009. 248–255. DOI:(http://dx.doi.org/10.1109/CVPR.2009.5206848)
ここ最近の ILSVRC のクラス分類部門の結果
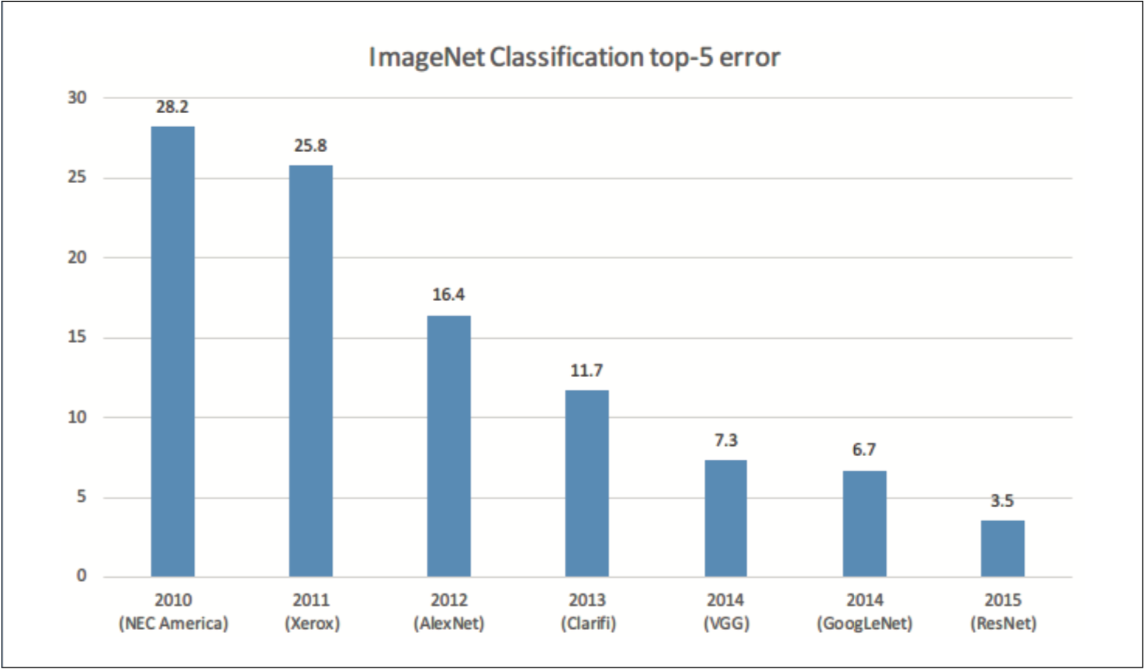 ILSVRC における優秀チームの成績の推移:縦軸は誤認識率、横軸は各年。横軸の括弧内には、チーム名または手法名を示す
ILSVRC における優秀チームの成績の推移:縦軸は誤認識率、横軸は各年。横軸の括弧内には、チーム名または手法名を示す
2012 年を境にディープラーニングによる手法 が常にトップに立っている。
VGG、GoogLeNet、ResNet の有名な3つのネットワークを紹介する
基本的なCNNだが、小さなフィルタによる畳み込み層が連続しているのが特徴
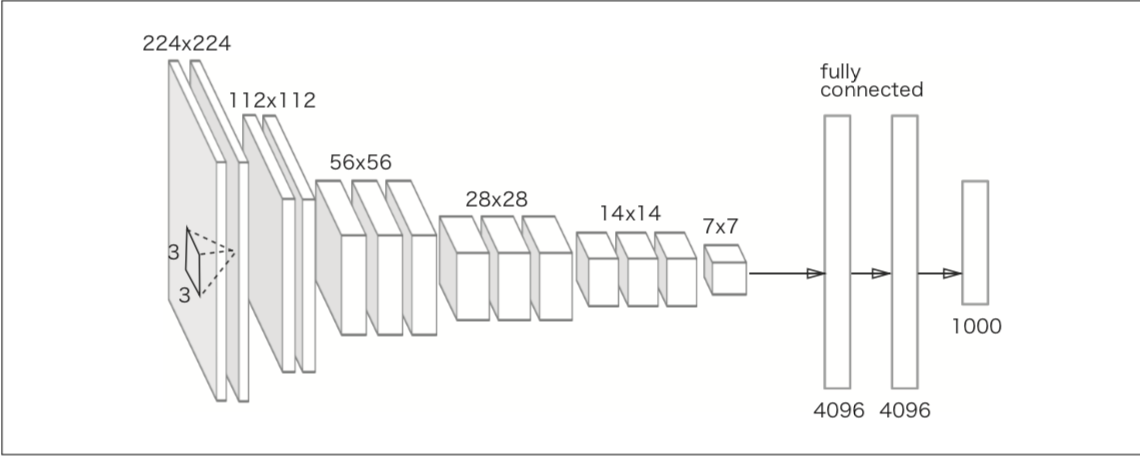 文献[1]を参考に作成された
文献[1]を参考に作成された
2014年のコンペティションで2位
VGG で注目すべきポイントは、3 × 3 の小さなフィルターによる畳み込み層を連続して行っている点。畳み込み層を 2 回から 4回連続し、プー リング層でサイズを半分にするという処理を繰り返し行い、最後に全結合層を経由して結果を出力する。
 文献[2]より引用
文献[2]より引用
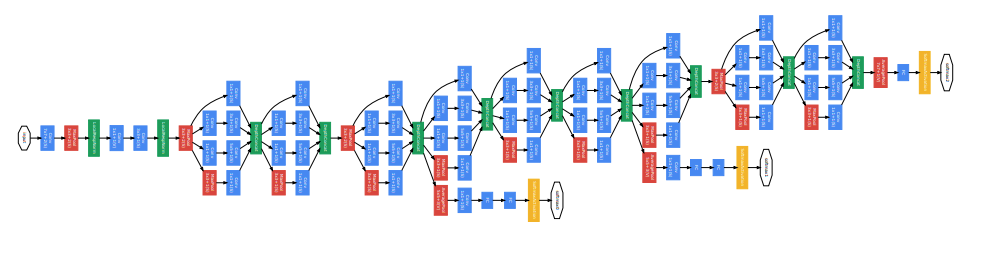
ネットワークが縦方向の深さだけではなく、横方向にも深さ(広がり)を持っているという点が特徴
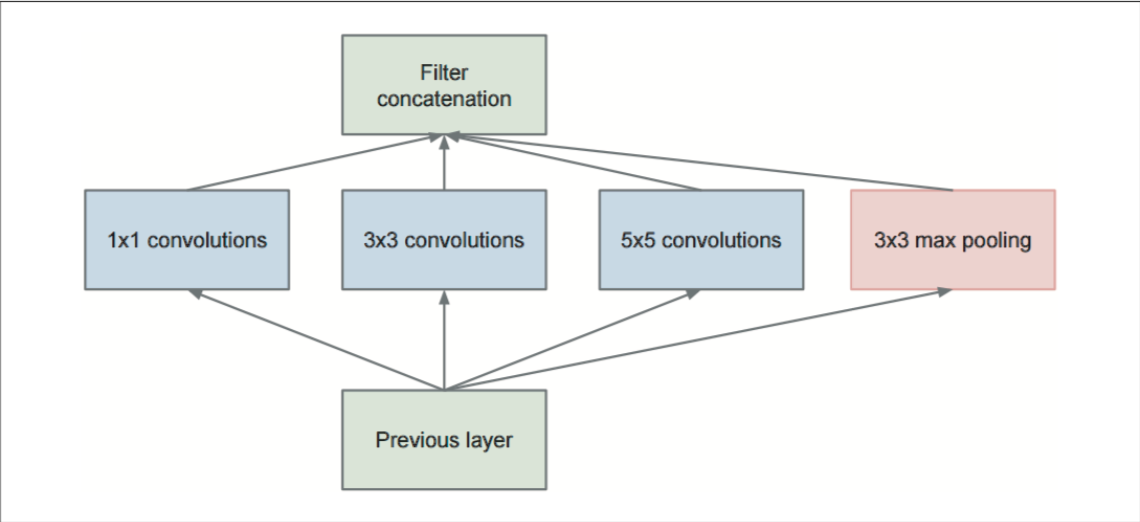 GoogLeNet のインセプション構造(文献[2]より引用)
GoogLeNet のインセプション構造(文献[2]より引用)
層をまたいで出力に合算するスキップ構造が特徴
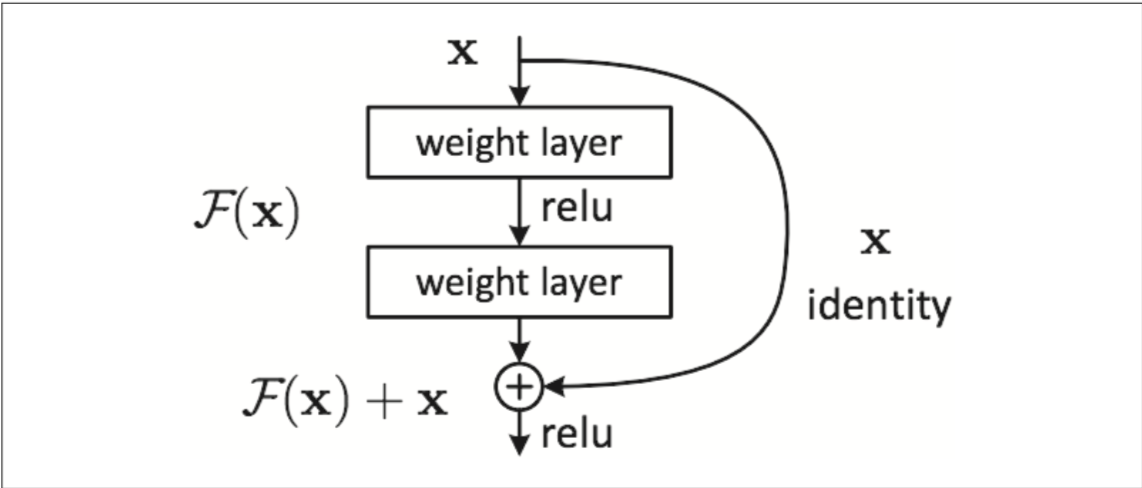 ResNet の構成要素(文献 [3] より引用):ここで「weight layer」とは畳み込み層を指す
ResNet の構成要素(文献 [3] より引用):ここで「weight layer」とは畳み込み層を指す
スキップ構造を取り入れることで、層を深くしても効率良く学習することができます。これは、逆伝播の際に、スキップ構造によって信号が減衰することなく伝わっていくから。
スキップ構造は入力データを“そのまま”流すだけ
-> 勾配が小さくなったり(または大きくなりすぎたり)する心配がなく、層を深くすることで勾配が小さくなる勾配消失問題が軽減
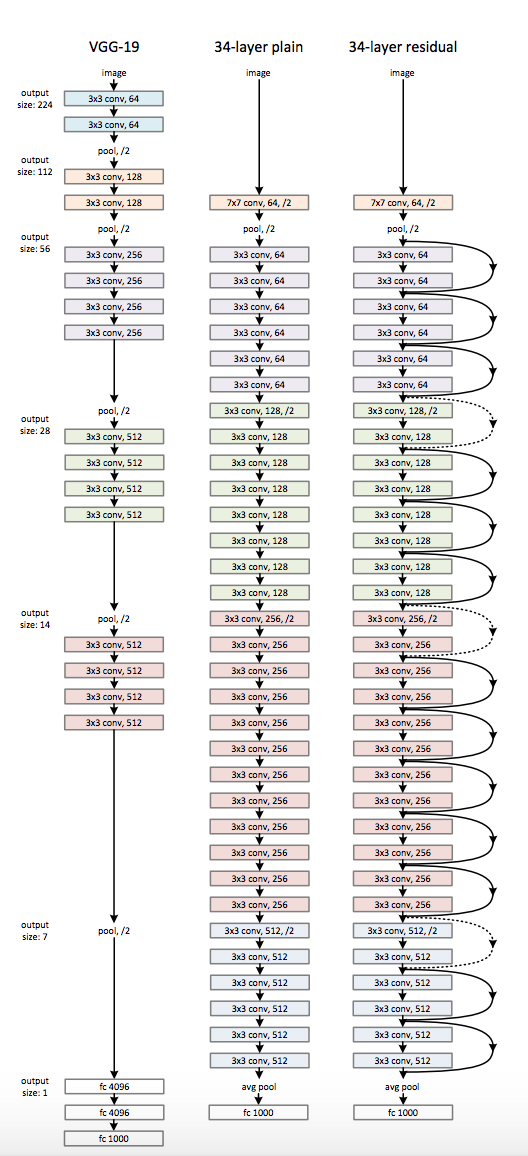 ResNet(文献 [3] より引用):ブロックが 3 × 3 の畳み込み層に対応。層をまたぐスキップ構造が特徴
ResNet(文献 [3] より引用):ブロックが 3 × 3 の畳み込み層に対応。層をまたぐスキップ構造が特徴
ResNetは上記写真の右「3-4 layer residual」
畳み込み層を 2 層おきにスキップしてつなぎ、 層を深くしていきます。なお、実験によって、150 層以上に深くしても認識精度は向上し続けることが分かりました。そして、ILSVRC のコンペティションでは、誤認 識率(上位 5 クラス以内に正解が含まれる精度の誤認識率)が 3.5% という、驚異的な結果を出した。
ImageNet の巨大なデータセットを使って学習した重みデータを有効活用する ということが実践的によく行われます。これは転移学習と言って、学習済みの 重み(の一部)を別のニューラルネットワークにコピーして、再学習を行いま す。たとえば、VGG と同じ構成のネットワークを用意し、学習済みの重みを 初期値とし、新しいデータセットを対象に、再学習(fine tuning)を行います。 転移学習は、手元にあるデータセットが少ない場合において、特に有効な手法 です。
ビッグデータとネットワークの大規模化により、ディープラーニングでは大量の演算を行う必要がある。
画像中から物体の位置の特定を含めてクラス分類を行う問題(複数のクラスも検出する)
画像中から物体の種類と物体の位置を特定する。
 物体検出の例(文献 [5] より引用)
物体検出の例(文献 [5] より引用)
R-CNNと呼ばれる手法が有名で、最初に物体と物体以外を識別する「候補領域抽出」を行い、抽出された領域に対してCNNでクラス分類を行っている
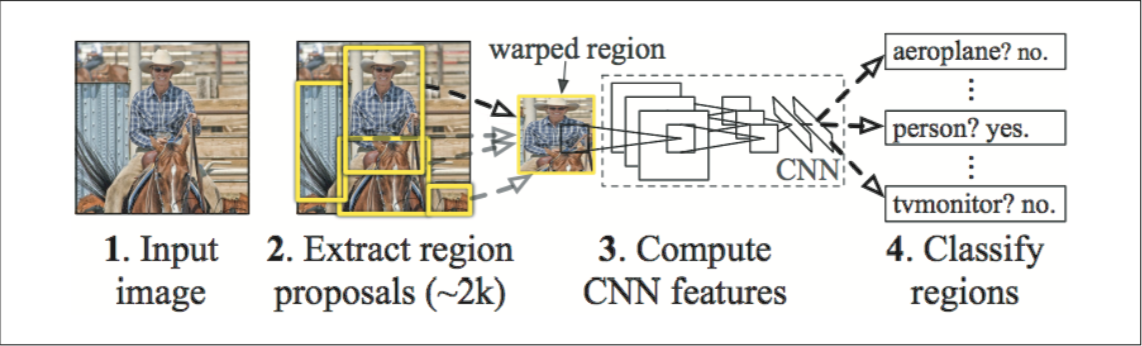 R-CNN の処理フロー(文献 [6] より引用)
R-CNN の処理フロー(文献 [6] より引用)
画像に対してピクセルレベルでクラス分類を行う。
ピクセル単位でオブジェクトごとに色ずけれられた教師データを使って学習を行う。
 セグメンテーションの例(文献 [5] より引用):左が入力画像、右が教師用のラベリング画像
セグメンテーションの例(文献 [5] より引用):左が入力画像、右が教師用のラベリング画像
FCN (Fully Convolutional Network=全てが畳み込み層のネットワーク)という手法が有名で、1回のforward処理ですべてのピクセルに対してクラス分類を行い、中間データの空間ボリュームを保持したまま最後の出力まで処理する。
また、最後にバイリニア補間による拡大をデコンボリューション(逆畳み込み演算)によって実現する。
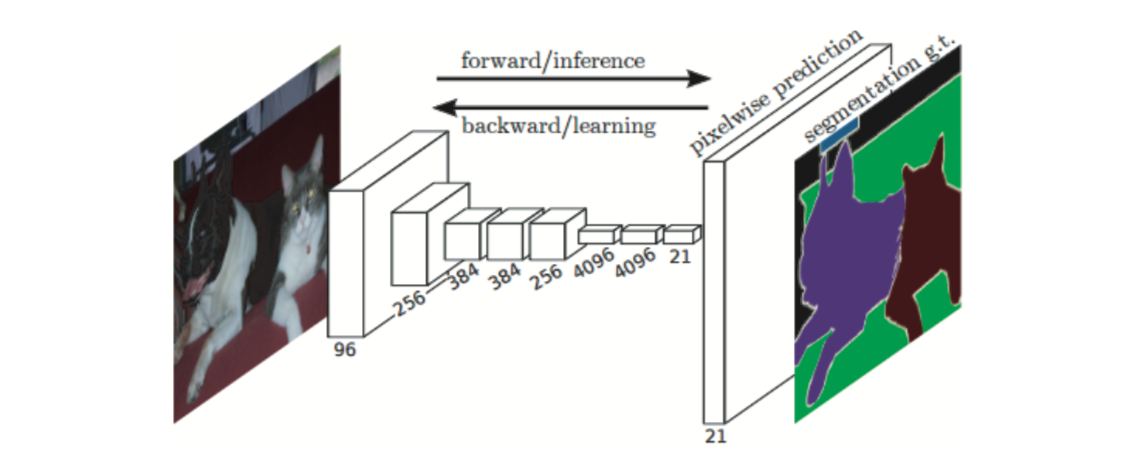 FCN の全体図(文献 [7] より引用)
FCN の全体図(文献 [7] より引用)
画像を与えると、その画像を説明する文章を自動で生成する研究
NIC (Neural Image Caption) ではCNNで画像認識、RNN(再帰的なネットワーク)で言語生成を行っている
 ディープラーニングによる画像のキャプション生成の例(文献 [8] より引用)
ディープラーニングによる画像のキャプション生成の例(文献 [8] より引用)
画像キャプションを生成する代表的な方法に、NIC (Neural Image Caption)と呼ばれるモデルがある
NIC は、画像から CNN によって特徴を抽出し、その特徴を RNN に渡す。
基本 的には、NIC は 2 つのニューラルネットワーク―― CNN と RNN――を組み合わせ たシンプルな構成です。それによって、驚くほど高精度な画像キャプションの生成が行える。
なお、画像と自然言語といったような、複数の種類の情報を組み合わせて処理することをマルチモーダル処理と言う。
以下の図で示す例は、2 つの画像を入力し、新しい画像を生成する という研究です
 論文「A Neural Algorithm of Artistic Style」による画像スタイル変換の例:左上が「スタイ ル画像」、右上が「コンテンツ画像」、下の画像が新たに生成された画像(画像は文献 [9] より引用)
論文「A Neural Algorithm of Artistic Style」による画像スタイル変換の例:左上が「スタイ ル画像」、右上が「コンテンツ画像」、下の画像が新たに生成された画像(画像は文献 [9] より引用)
ゴッホの描画スタイルを、コンテンツ画像に適用するように指定すれば、ディープラーニングが、指定されたとおりに新しい絵画を描いてくれ る。
これは「A Neural Algorithm of Artistic Style」[9] という論文の研究で、発表されるやいなや世界中で多くの注目を集めた。
新しい画像を生成する際に、何の画像も必要とせ ずに新たな画像を描き出すといった研究も行われている。
 DCGAN によって新たに生成されたベッドルームの画像(文献 [10] より引用)
DCGAN によって新たに生成されたベッドルームの画像(文献 [10] より引用)
画像は本物の写真のように見えるかもしれませんが、これらの画像は、 DCGAN によって新たに生成された画像です。つまり、DCGAN が描き出す画像 は、まだ誰も見たことがない画像(学習データには存在しない画像)であり、ゼロから新たに生成された画像なのです。
DCGAN は、Generator(生成する人)と Discriminator(識別する人)の 2 つの ニューラルネットワークを利用している。
Generator が本物そっくりの画像を生成
-> Discriminator は、 Generator が生成した画像 か、それとも実際に撮影された本物の画像か――を判定
両者を競わせるように学習させていくことで、Generator は、より精巧な騙し画像の技術 を学習し、Discriminator は、より高精度に見破ることができる鑑定師のように成長していく
切磋琢磨して成長した Generator は、最終的には本物と見間違うほどの画像を描き出せる能力を身につける場合がある。
CNNベースのSegNetは走路環境のセグメンテーションを高精度で行う。
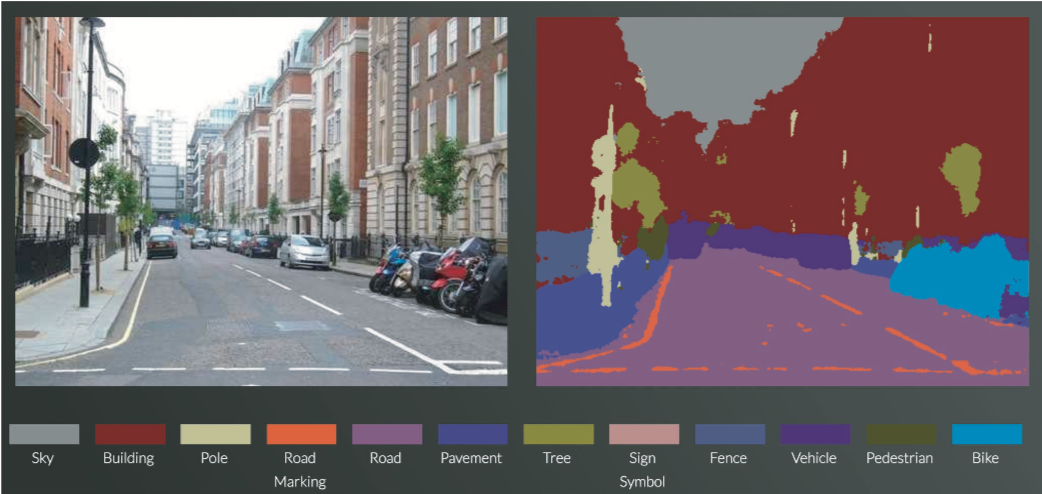 ディープラーニングによる画像のセグメンテーションの例:道路や車、建物や歩道などが高 精度に認識されている(文献 [11] より引用)
ディープラーニングによる画像のセグメンテーションの例:道路や車、建物や歩道などが高 精度に認識されている(文献 [11] より引用)
上記画像に示すように、入力画像に対してセグメンテーション(ピクセルレベルの 判定)を行っている。
結果を見ると、道路や建物、歩道や木、車やバイクなどを、 ある程度正確に判別していることが分かる。
強化学習では、エージェントと呼ばれるものが、環境の状況に応じて行動を選択し、その行動によって環境が変化するというのが基本的な枠組み。
環境の変化に よって、エージェントは何らかの報酬を得る。強化学習での目的は、より良い報酬が得られるようにエージェントの行動指針を決めるという点にある
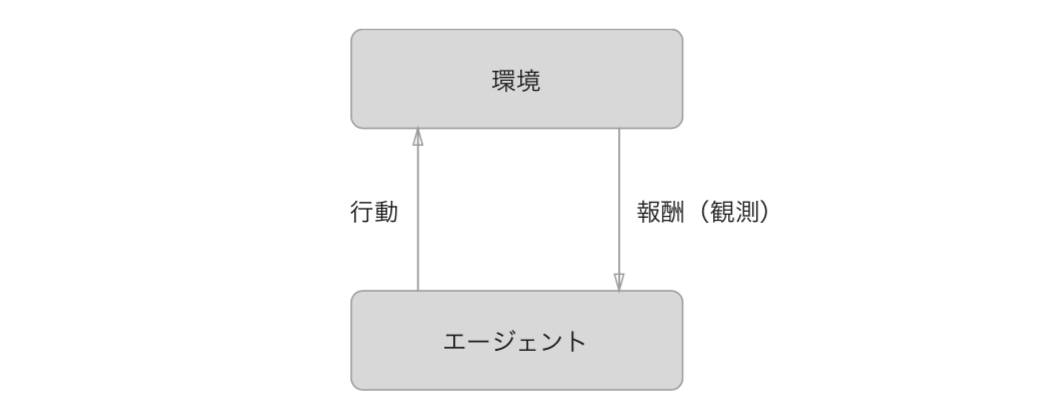 強化学習の基本的な枠組み:エージェントは、より良い報酬を目指して自立的に学習する
強化学習の基本的な枠組み:エージェントは、より良い報酬を目指して自立的に学習する
ディープラーニングを使った強化学習の手法として、Deep Q-Network(通称、 DQN)[44] という手法がある
DQNは、動作に対する価値観数をCNNで近似することで、画像に対しての動作を最適化する学習を行う
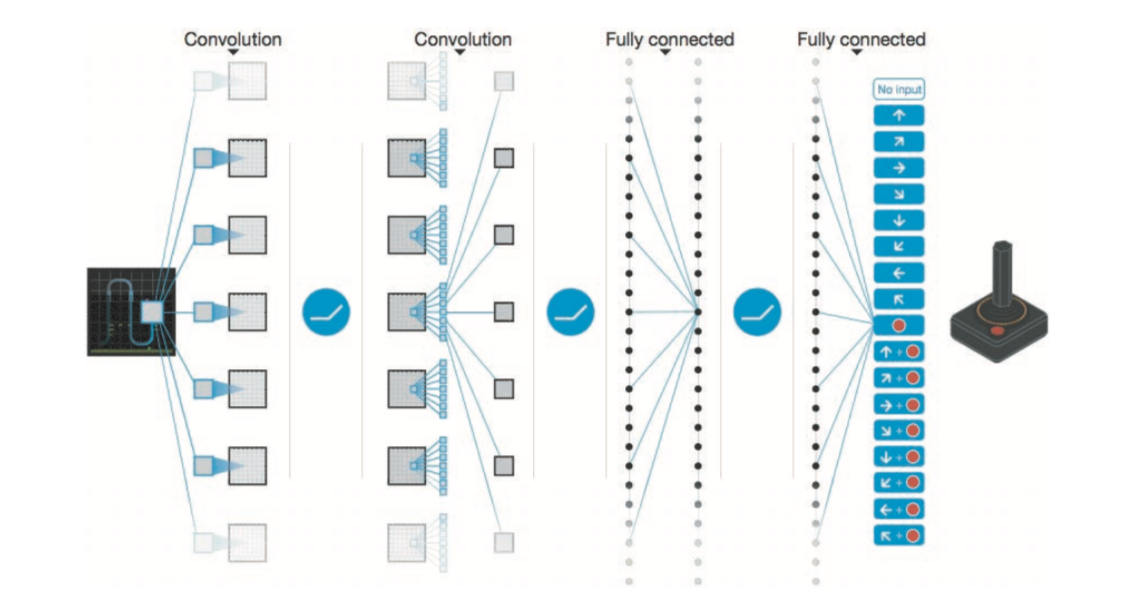 [12] Volodymyr Mnih et al(2015):Human-level control through deep reinforcement learning. Nature 518, 7540 (2015), 529 – 533.
[12] Volodymyr Mnih et al(2015):Human-level control through deep reinforcement learning. Nature 518, 7540 (2015), 529 – 533.
人工知能である AlphaGo [13] が囲碁のチャンピオンを破ったというニュース は大きな注目を集めました。この AlphaGo という技術の内部でも、ディープラーニングと強化学習が用いられています。AlphaGo では、3,000 万個のプロの棋譜を与えて学習させ、さらに、AlphaGo 自身が自分自身と対戦することを何度も繰り返しながら、学習を積み重ねたそうです。なお、AlphaGo と DQN は両方とも、Google の Deep Mind 社によって行われた研究です。今後も、Deep Mind 社の活躍には目が離せません。
本章では、ディープな CNN を実装し、手書き数字認識において 99% を超 える高精度な認識結果を得た。
ディープラーニングのトレンドや実用例、また、高速化に向けた研究や未来を感じさせる研究例を紹介した。
世界中の研究者や技術者たちは、これからも活発に研究を続け、そして、今では想像もつかないような技術が現実化されるでしょう。
[1] Karen Simonyan and Andrew Zisserman(2014):Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556[cs](September 2014).
[2] Christian Szegedy et al(2015):Going Deeper With Convolutions. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[3] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun(2015):Deep Residual Learning for Image Recognition. arXiv:1512.03385[cs](December 2015).
[4] Matthieu Courbariaux and Yoshua Bengio(2016):Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. arXiv preprint arXiv:1602.02830 (2016).
[5] Visual Object Classes Challenge 2012 (VOC2012)(http://host.robots.ox .ac.uk/pascal/VOC/voc2012/)
[6] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik(2014):Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In 580–587.
[7] Jonathan Long, Evan Shelhamer, and Trevor Darrell(2015):Fully Convolutional Networks for Semantic Segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[8] Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan(2015):Show and Tell: A Neural Image Caption Generator. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[9] neural-style "Torch implementation of neural style algorithm"(https: //github.com/jcjohnson/neural-style/)
[10] Alec Radford, Luke Metz, and Soumith Chintala(2015):Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv:1511.06434[cs](November 2015).
[11] SegNet Demo page(http://mi.eng.cam.ac.uk/projects/segnet/)
[12] Volodymyr Mnih et al(2015):Human-level control through deep reinforcement learning. Nature 518, 7540 (2015), 529 – 533.
[13] David Silver et al(2016):Mastering the game of Go with deep neural networks and tree search. Nature 529, 7587 (2016), 484 – 489.