Dragon Arrow written by Tatsuya Nakaji, all rights reserved 
updated on 2020-06-20

単一の数値評価メトリックを使用することで、効率的に、またはそれらの決定を行う際のチームの効率を向上できる。
再現率 (感度、真陽性率、Recall)とは、陽性のサンプルのうち、実際に陽性だと予測できる確率。
式: TP / (TP + FN)
例: 病気の人の中で検査で発見できる確率
適合率 (精度、陽性反応的中度、Precision)とは、陽性の予測が正しい確率。
式: TP / (TP + FP)
例: 検査で陽性が出たときに実際に病気である確率
特異度 (真陰性率、Specificity)とは、陰性の予測が正しい確率。
式: TN / (FP + TN)
例: 元気な人に対して、病気でないと判断する確率
正確度 (Accuracy)とは、予測が正しい確率。
式: (TP + TN) / (TP + FP + TN + FN)
例: 患者を病気か元気かを正しく予測できる確率
F1スコア 再現率 R と適合率 P の調和平均。
式: \( \frac{ 2 }{ \frac{ 1 }{ P }+ \frac{ 1 }{ R } } \)
Harmonic mean (調和平均)
TPはpositive(陽性)と予測した結果がTrueであることをいう。
TNはnegative(陰性)と予測した結果がTrueであることをいう。
FPはpositive(陽性)と予測した結果がFalseであることをいう。
FNはnegative(陰性)と予測した結果がFalseであることをいう。
実際は正 (Positive) | 実際は負 (Negative) | |
|---|---|---|
| 予測が正 (Positive) | TP True Positive | FP False Positive 第1種の誤り |
| 予測が負 (Negative) | FN Flase Negative 第2種の誤り | TN True Negative |
 評価メトリック その1
評価メトリック その1
 評価メトリック その2
評価メトリック その2
以下の例でいうと、
satisficing metric(満たすべき指標) => 実行時間100ms
optimizing metric(最適化すべき指標) => 精度の最適化
A,Bは両方とも実行時間100msを満たしテイルが、精度の最適化において優位なBが最適な要件を満たす選ぶべきモデルと結論する。
 satisficing and optimizing metric
satisficing and optimizing metric
開発セットはバリデーションデータ(検証データ)のことを指す。
訓練データ(train set)は、モデルを訓練して構築するためのデータ
バリデーションデータ(dev set)は、モデルのハイパーパラメータを決めるためのデータ
テストデータ(test set)は、モデルの推定性能を、最終的に決定するためのデータ
ちなみに、ディープラーニングではデータが多いことが前提なのでやることはないが、バリデーションデータを用いずにトレーニンデータのみから交差検証によりハイパーパラメータを選ぶ方法もある
訓練セット、開発セット、テストセットは同じ分布が望ましいが、訓練データに関しては、分布が違っても理にかなっていることもある。
訓練データに違う分布のデータを訓練に追加することで、アルゴリズムが強化されることもあるので、訓練データに関しては、試した結果次第。
開発セットとテストセットは必ず同じ分布にする。
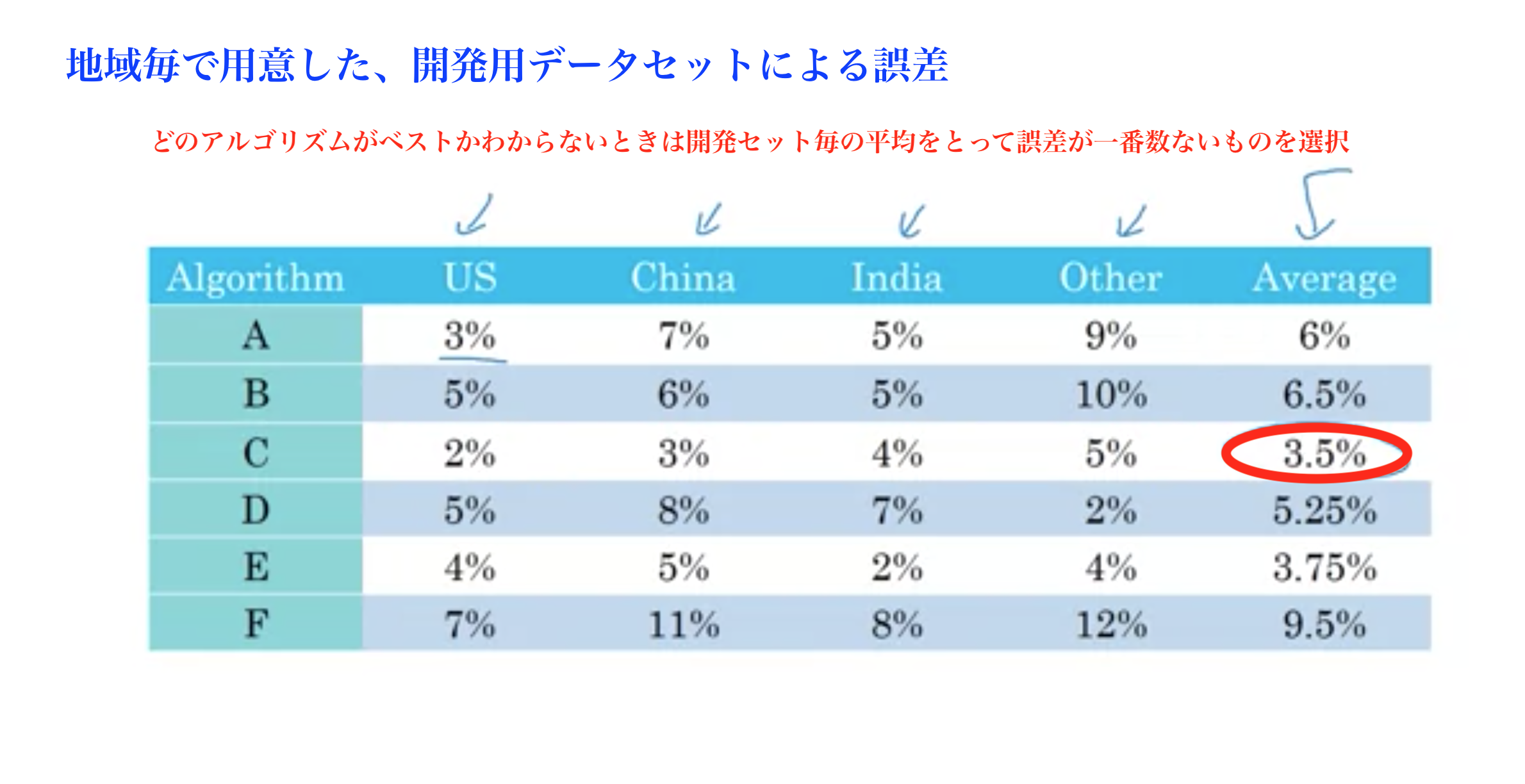
例: 猫の画像分類器の開発/テストセット
以下の8地域でデータが取得できたときの開発セットとテストセットの選び方
Regions:
NG: データを国毎で開発/テストに分ける(開発セットをランダムな4地域、テストセットを残りの4地域など)
理由: 開発セットとテストセットで分布が違うと、予測精度が大きく変わりうる。
推奨: データをシャッフルして無作為に開発/テストに割り振る(開発/テストで同じ分布を適用する)
理由: 開発セットとテストセットで同じ分布になる
全体データを100%で表すとき、
メジャーな分割の仕方
以下はデータが少ないとき(データ数10000以下)にとても理にかなった分割だった.
・訓練 70% テスト30%
・訓練 60% 開発 20% テスト20%
現在はビッグデータ時代で、より大きなデータサイズを扱うことができる
データ数が1,000,000
・訓練 98% 開発 1% テスト1% (開発/テストセットはそれぞれ10,000もあれば十分)
医療画像の分類で以下のように一般人、医者、専門医、専門医チームで誤差を測定した場合、人間レベルの誤差は、一番精度が良い専門医チームの誤差と考える。同時にベイズ誤差が0.5%以下だとわかる。
ベイズ誤差の代理。
達成可能な最小の予測誤差のこと。irreducible error(既約誤差)と同じ。
未知であったり予測不可能な要因や単なる偶然により、減少させることはできない誤差のこと。
モデルの調整によってさらに低減することができる誤差。
「2乗偏りによる誤差」および「分散による誤差」にさらに分解することができる。
バイアス:モデルの偏りの大きさ。
バリアンス:モデルの過学習のしやすさ。
バイアスとバリアンスはトレードオフの関係にある。
モデルがシンプルな場合:高バイアス・低バリアンス
モデルが複雑な場合:低バイアス・高バリアンス
回避可能なバイアス: (訓練誤差) - (人間レベルの誤差)
分散: (汎化誤差) - (訓練誤差)
 人間レベルのパフォーマンスとの比較
人間レベルのパフォーマンスとの比較
機械学習が人間レベルのパフォーマンスを大幅に上回る多くの問題
構造化されたデータ (データベースに溜まったデータを使用)
自然認識ではない(natural perception 人間がシーンを視覚的に取り込み、解釈するプロセス)ではない
その他
バイアスと分散の減少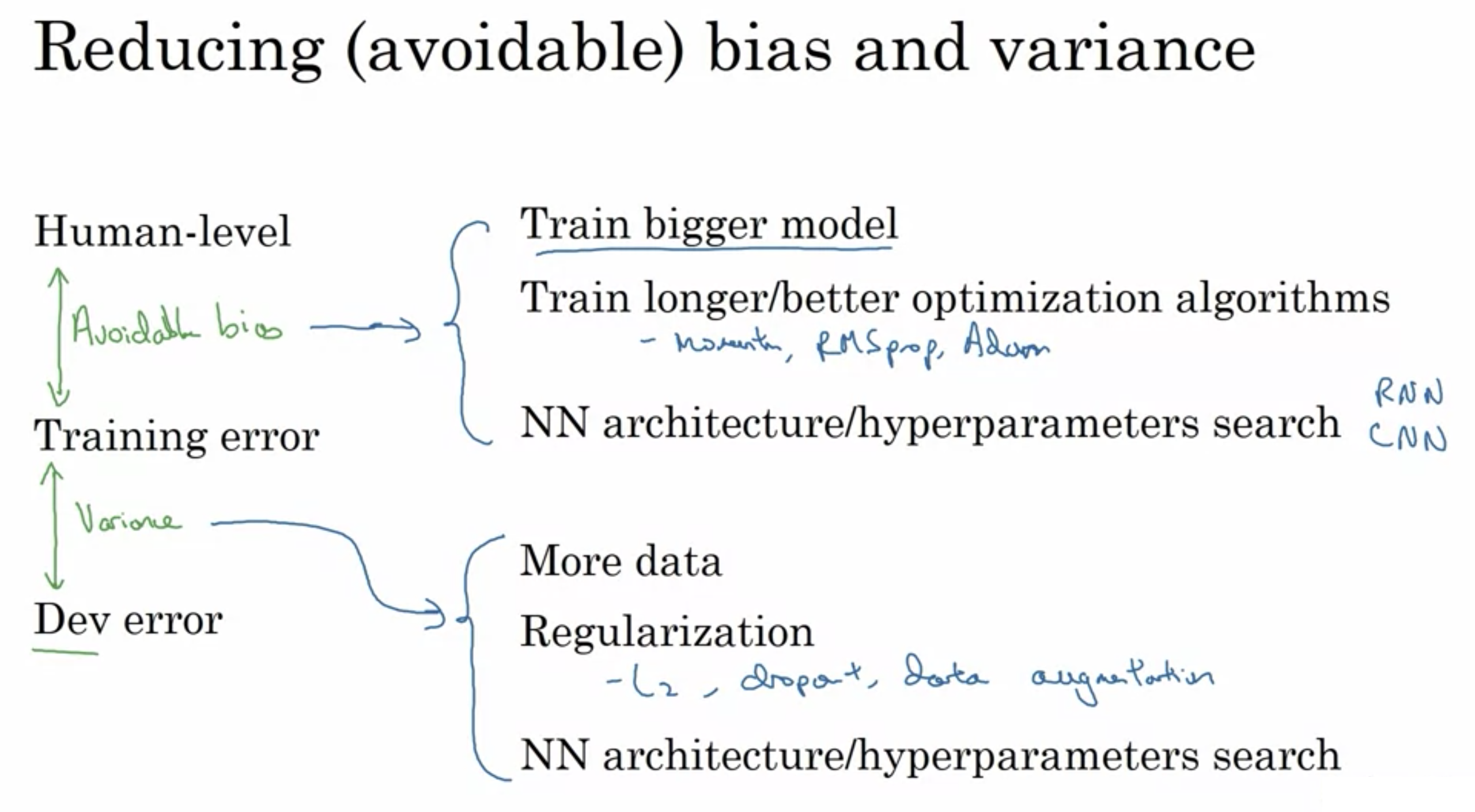 バイアスと分散の減少
バイアスと分散の減少
猫の検出器を製作し、精度が90%、誤差が10%とする。
開発セットの中で、予測を間違えた100個のサンプルを取得し、そのうち5%(5個)が犬だったとする。
犬の誤認を解決しても、開発セットの誤差はほとんど改善されない(例えば、10%->9.5%)
開発セットの中で、予測を間違えた100個のサンプルを取得し、そのうち50%(50個)が犬だったとする。
犬の誤認を解決することで、開発セットの誤差を非常によく改善ができる(例えば、10%->5%)

複数のアイデアを並行して評価する
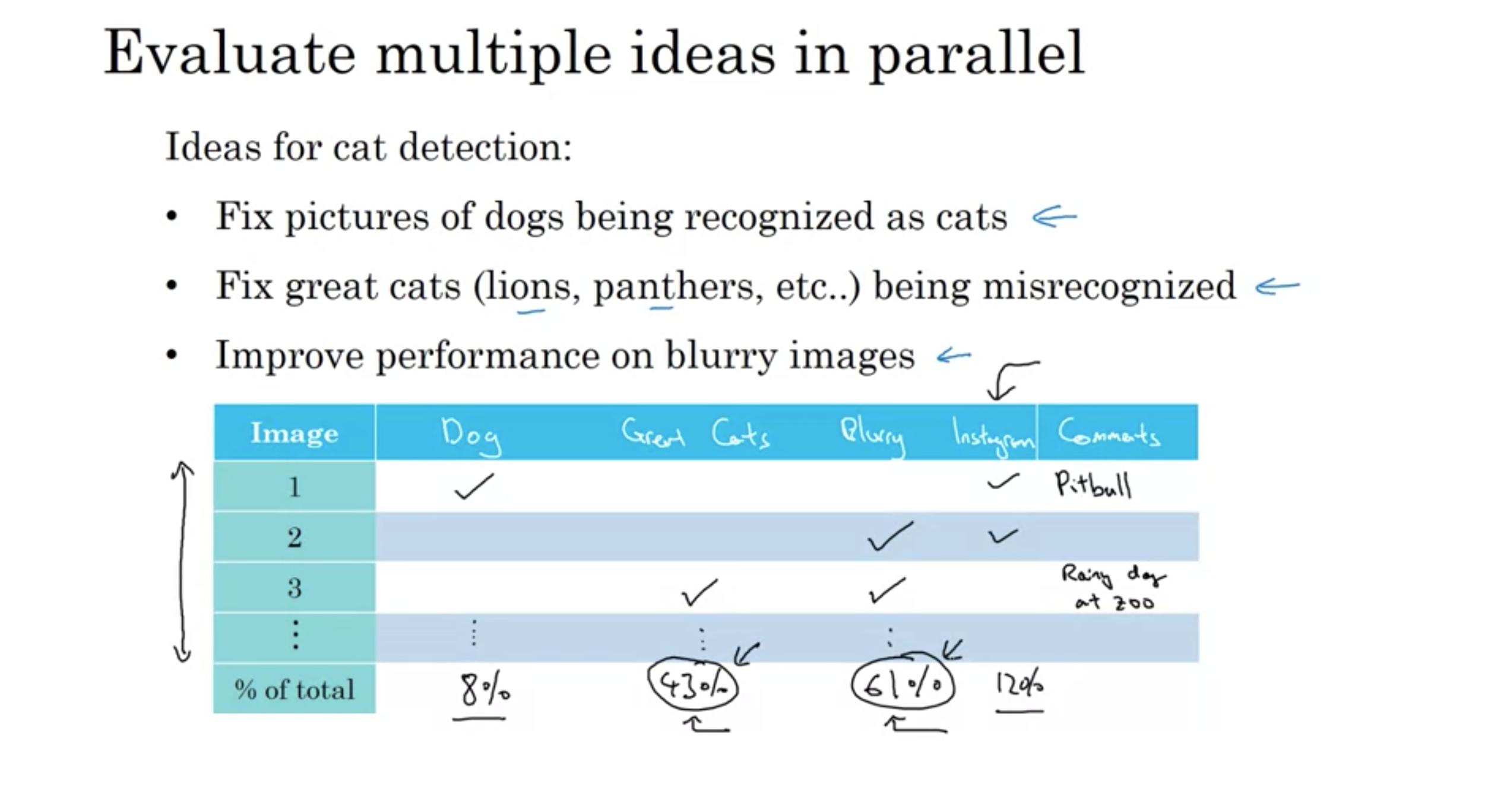 並行した複数のアイデアの評価
並行した複数のアイデアの評価
誤認サンプルから
猫検出器のアイデア
それぞれの誤認の種類が、全体の何%かを計算することで、パフォーマンスをどの程度改善できるかの上限がわかる。
猫の誤認8%、大きな猫の誤認43%、ぼやけた画像の誤認61%、インスタグラムの誤認12%とする。
このような場合、二つのうち(大きな猫の誤認、ぼやけた画像の誤認)の一つを選ぶかもしれない
あるいは自分のチームに十分な人員があるなら、二つの異なるチームを作る(大きな猫のエラーを改善するチームと、ぼやけた画像のエラーを改善するためのチーム)
修正を行う優先度を決めるのは、誤差解析による各誤差の大きさと解決にかかる時間・コストの規模次第
データに誤ってラベル付けされたデータがあった場合の対応。
深層学習アルゴリズムは、トレーニングセットのランダム誤差に対して非常に堅牢である。
エラーまたは誤ってラベル付けされた例である限り、それらのエラーがランダムから離れすぎていない限り、ラベラーが注意を払っていなかったか、誤ってキーボードの誤ったキーをランダムに叩いた可能性がある。
エラーがかなりランダムな場合は、エラーをそのままにして修正にあまり時間をかけない。
トレーニングセットに入ってラベルを調べ、修正しても害はないが、エラーに実際の割合が多すぎない限りパフォーマンスにほとんど害はないかもしれない。
一方で、深層学習アルゴリズムは、系統的エラーに対してそれほど堅牢ではない。
白い犬を猫とラベル付けした場合、白い犬を猫と学習するので問題である。
まとめ:
ランダム誤差やそれに近い誤差の場合は、ディープラーニングにとってそれほど悪いものではない。
ランダム誤差(Random error): 偶然誤差とも呼ばれ、測定ごとにばらつく誤差。この誤差は毎回ランダムな値をとるので測定後に取り除くことができない。(例: コインを投げた結果の誤差)
2週目1のエラー解析で、誤認サンプル100を対象にした評価アイデアを紹介したが、さらに「不適切なラベルデータの誤認」を追加。
開発セットの誤差が10%、不適切ラベルによる誤差が0.6%、それ以外の原因での誤差が9.4%の時、ラベルの修正はさほど問題ではない。(もし望むなら、ラベルを修正しても良いが、すぐにやらなければならないことではない。)
開発セットの誤差が2%、不適切ラベルによる誤差が0.6%、それ以外の原因での誤差が1.4%の時、ラベルの修正は重要な問題である。
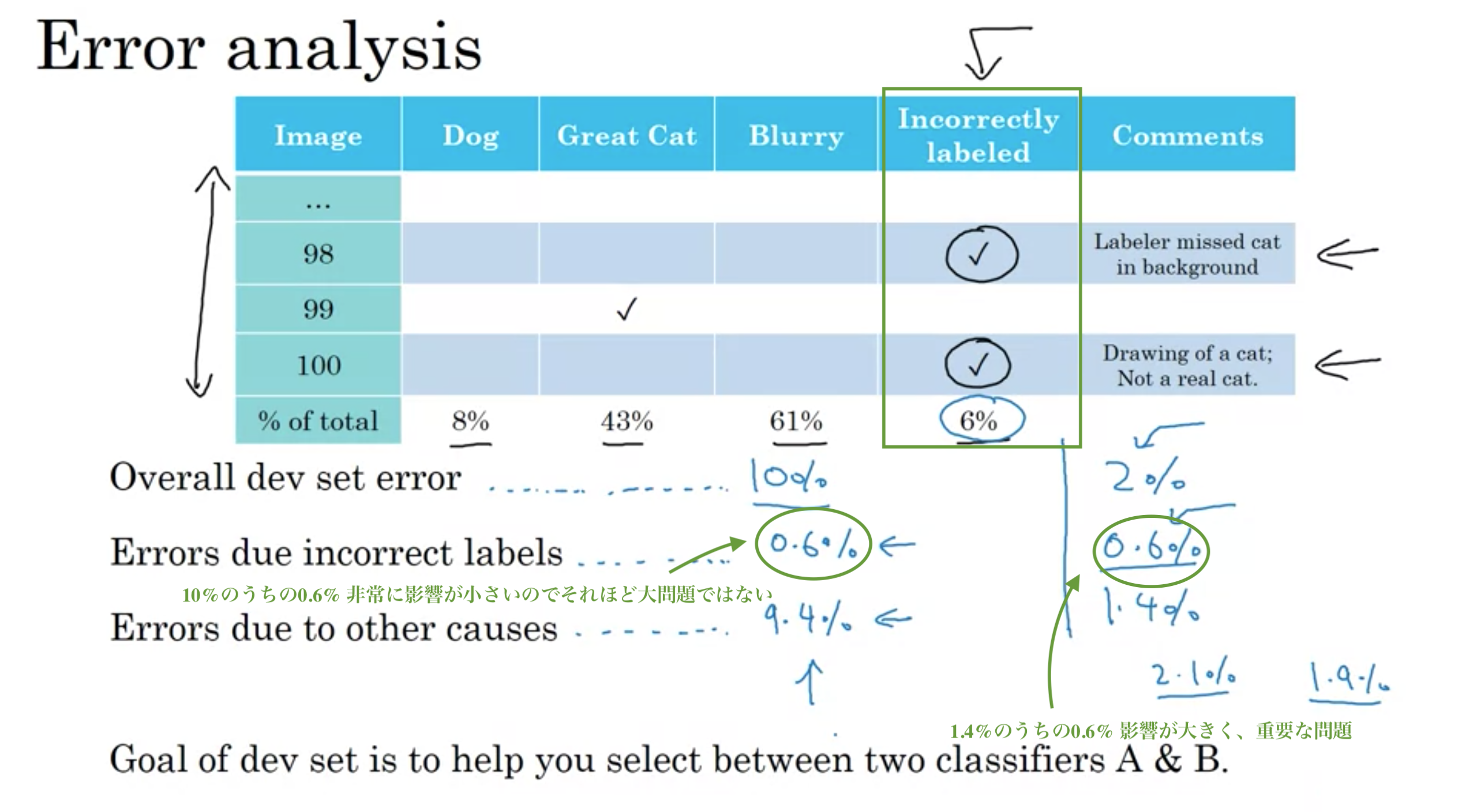 誤差解析における誤ったラベルの誤認
誤差解析における誤ったラベルの誤認
不適切な開発/テストセットのサンプルの収集
初めて新しい問題に取り組む場合、最初のシステムを過度に考えすぎたり、複雑にしすぎない。
すばやく簡単に何かを構築し、それを使用して、システムを改善する方法の優先順位付けをする。
以前にかなりの経験を持っているアプリケーション領域で作業している場合にはあまり適用されない。
しかし、同じ課題に対する学術文献や資料がある場合は、初めから複雑なシステムを構築しても問題ない。

目標が新しいアルゴリズムを作ることではなく、何かうまく機能する物を作ることである場合
迅速かつ汚いモデルを構築(コスト時間を無駄にしない)
=> バイアス/分散の分析
=> 誤差分析
=> 分析の結果を使用して、改善すべき場所の優先順位付け
ディープラーニングは多くのデータが必要なため、色々なところからデータを集めたりするが、その結果データが開発データやテストデータと異なる分布になるかもしれない。
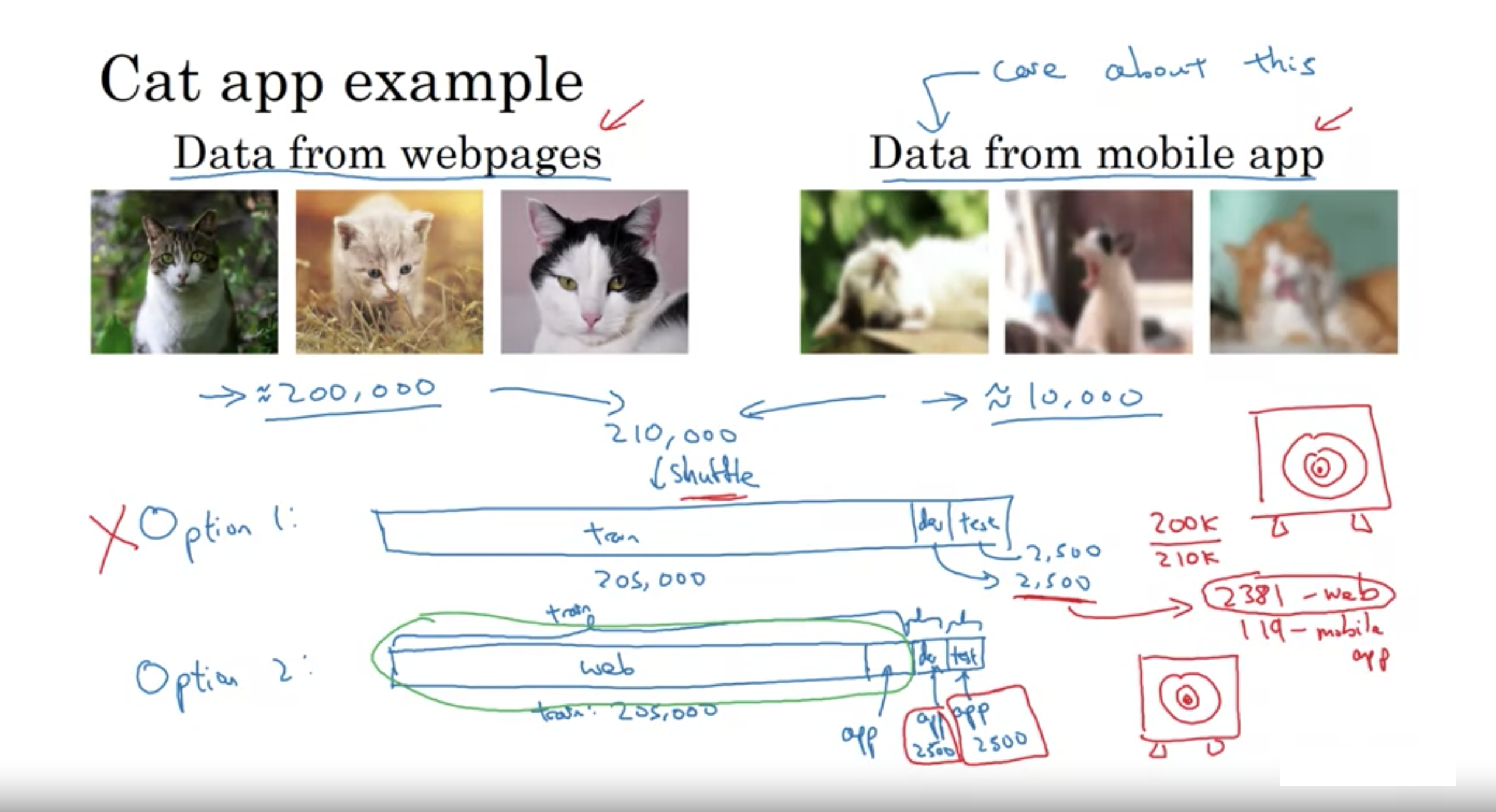
例えば、猫分類器のデータ収集で、モバイルアプリの画像(10,000)とWebページのクローリングした画像(200,000)を使用するとする。
最終的なシステムが、モバイルアプリの分布画像でうまく機能することである。
この場合、モバイルアプリの画像だけでは少ないため、Webの画像を使いたいが、モバイル画像の分布とは違う分布であるというジレンマが発生する。そこで以下のような解決策がある。
ただし、選択肢2を推奨
選択肢1: モバイル画像とWeb画像を全て混ぜてシャッフルし、訓練/開発/テストにランダムに割り当てる (訓練205,000 開発5,000 テスト,5000など)
利点: 訓練、開発、テストが全て同じ分布になる
大きな欠点: 開発セットの2500データは、適応させたいモバイルアプリの画像の分布ではなく、多くがWebページの分布からの画像である
開発セットは、2500×(200,000/210,000)=約2381がWebページ分布のデータになり、2500-2381=119がモバイル分布の画像になる
選択肢2: 訓練に、全Web画像と一部モバイル画像を適用し、開発セットとテストセットには全てモバイル画像を用いる
(訓練 205,000 (Webの200,000+モバイルの5000) 開発 5000(モバイルのみ) テスト 5000(モバイルのみ))
利点: ターゲットを目的の場所(モバイルアプリでうまく機能すること)に向けることができる
欠点: 訓練セットの分布が開発/テストの分布と異なること。(しかし、このデータの分割の仕方は長い目で見ると、良いパフォーマンスに繋がる)
 データの異なる分布と対策
データの異なる分布と対策
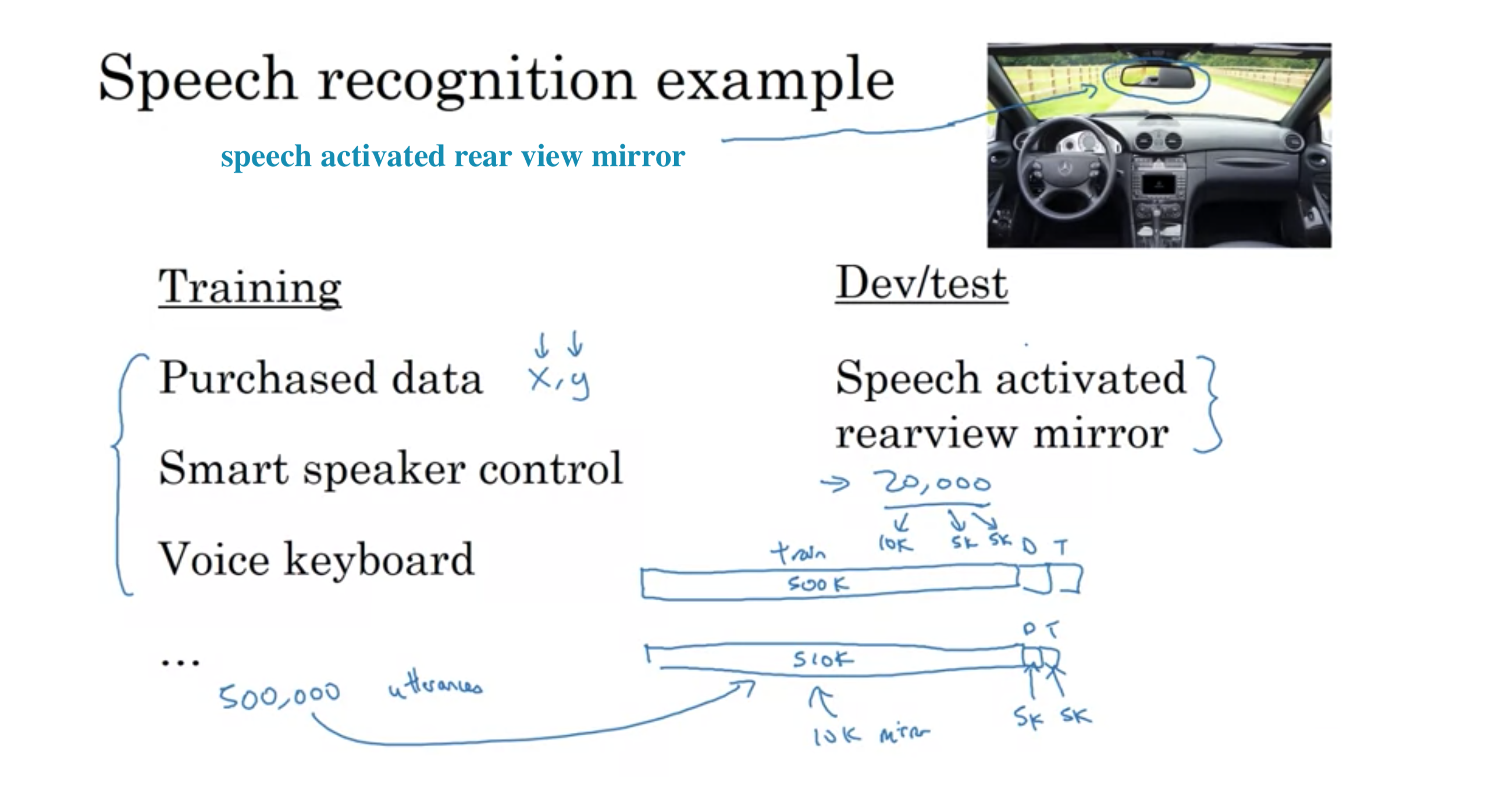
車の音声作動式バックミラー
トレーニングでは、多くのデータを用意するために、音声起動のバックミラーからではなく、他の音声認識アプリケーションからデータを持ってくる。データの分割は以下の通り
訓練: 500,000発話 (音声認識データベンダーから購入したデータ、スマートスピーカー、音声起動キーボード)
開発: 10,000 (音声作動式バックミラー)
テスト: 10,000 (音声作動式バックミラー)
または
訓練: 510,000発話 (500,000+10,000 (購入したデータ、スマートスピーカー、音声起動キーボード)+(音声作動式バックミラー) )
開発: 5,000 (音声作動式バックミラー)
テスト: 5,000 (音声作動式バックミラー)
 音声認識での異なる分布
音声認識での異なる分布
訓練セットの分布が、開発/テストセットの分布と一致しないとき、訓練データの一部から、train-dev set "訓練-開発データ"を作成
 異なる分布でのバイアスと分散
異なる分布でのバイアスと分散
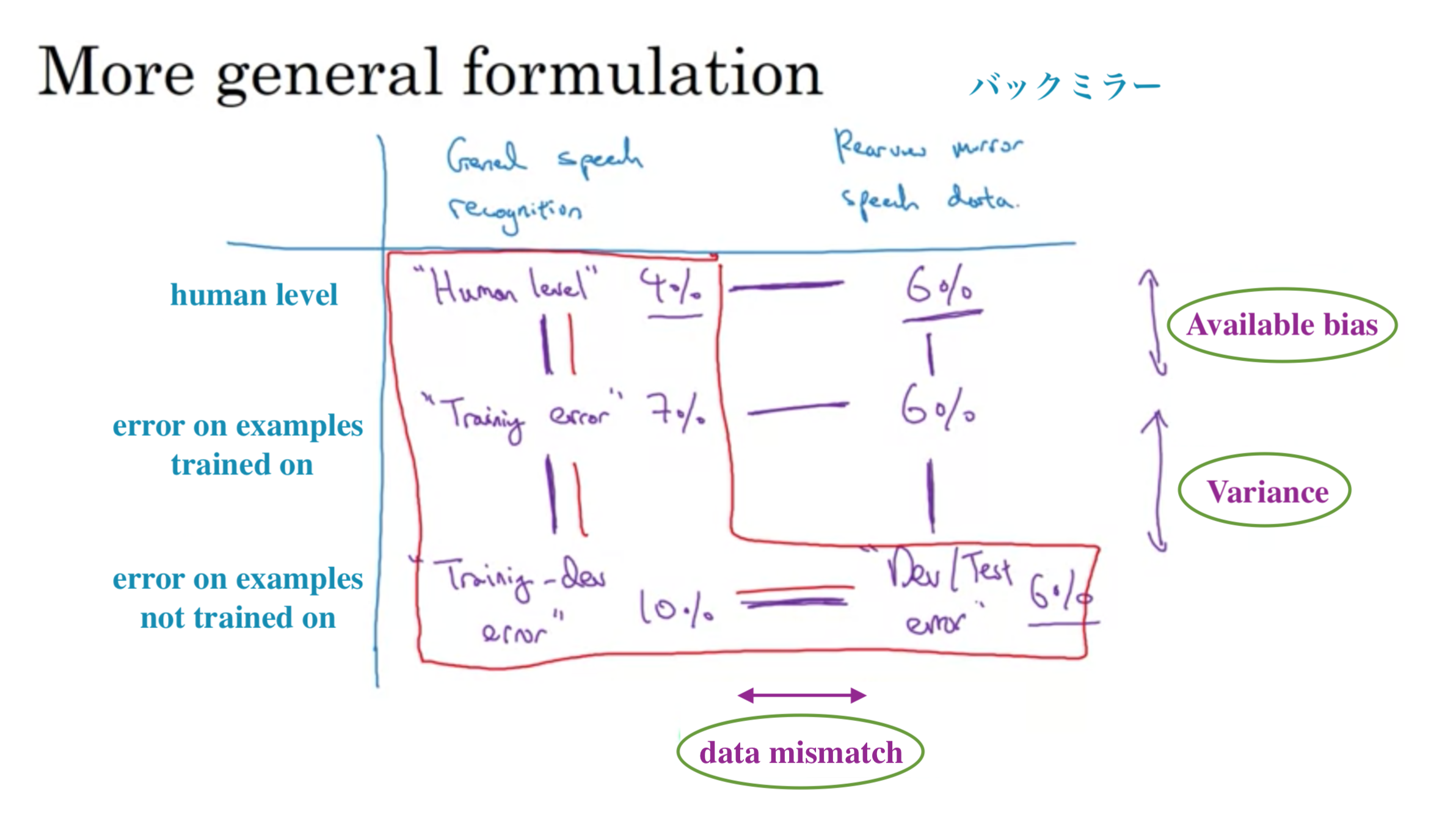 音声作動バックミラーによる具体例
音声作動バックミラーによる具体例
対処の手順
・手動で誤差分析を実行して、トレーニングと開発/テストセットの違いを理解する
(例えば、車のノイズや道路のノイズ)
・トレーニングデータを開発/テストセットに類似させる または 開発/テストセットに類似したデータをもっと集める
(例えば、車内のノイズをシミュレートする)
人工的なデータの合成
 人工的なデータの合成
人工的なデータの合成
多くの人が考えた独特な手法の1つとして、優れたコンピュータグラフィックを備えたビデオゲームを見つけ、ゲームの画像から膨大なデータを取得する。しかし以下の問題が起きる。
ビデオゲームに20台の車の種類しかなかった時に、世界には20よりはるかに多くのデザインがあるので、合成訓練データに20台の車しかない場合ニューラルネットワークは20台の車に過学習指定しまう。
 人工的なデータ合成
人工的なデータ合成
まとめ
データ不一致(train-devとdev/testの誤差が大きい)が起きた場合、データ不一致を理解し2つのデータの分布がどのように異なるか洞察を得るために、誤差解析や訓練データや開発セットの確認する。
次に、開発セットに少し似た訓練データを取得する方法を見つけることができるかどうかを確認する。
類似データを集める方法の1つは、人工的なデータの合成。音声認識では、音声データの合成で、認識システムのパフォーママンスが大幅に向上した。したがってこの方法はうまく機能する。
ただし、人工データ合成を使用している場合は、考えられるすべての例の空間のごく一部のデータのみを誤ってシミュレートしていないかどうかに注意が必要 (例: ビデオゲームのグラフィック画像を合成に使った結果、ゲーム画像しか予測できなくなる)
転移学習
ディープラーニングの最も強力なアイデアの1つで、ある領域で学習させたモデルを、別の領域に適応させる技術。 具体的には、広くデータが手に入る領域で学習させたモデルを少ないデータしかない領域に適応させたり、シミュレーター環境で学習させたモデルを現実に適応させたりする技術
以下の例で行ったことは、画像認識から学んだ知識を取り入れて、それを放射線診断に適用または転送したこと。
これが役立つ理由は、エッジの検出、カーブの検出、ポジティブなオブジェクトの検出など、多くの低レベルの機能です。
非常に大きな画像認識データセットで事前学習してるので、さまざまな画像のどの部分がどのように見えるか、線、点、曲線などについての知識、オブジェクトの小さな部分についての知識を持っており、放射線検査はもう少し早く、より少ないデータで学習ができる。
転移先のモデルにデータが少ない場合が転移学習は有効であるが、転移元のデータが少なく、転移先のデータの方が多い場合、転移学習をしても害はないが、意味のある効果も期待できない。
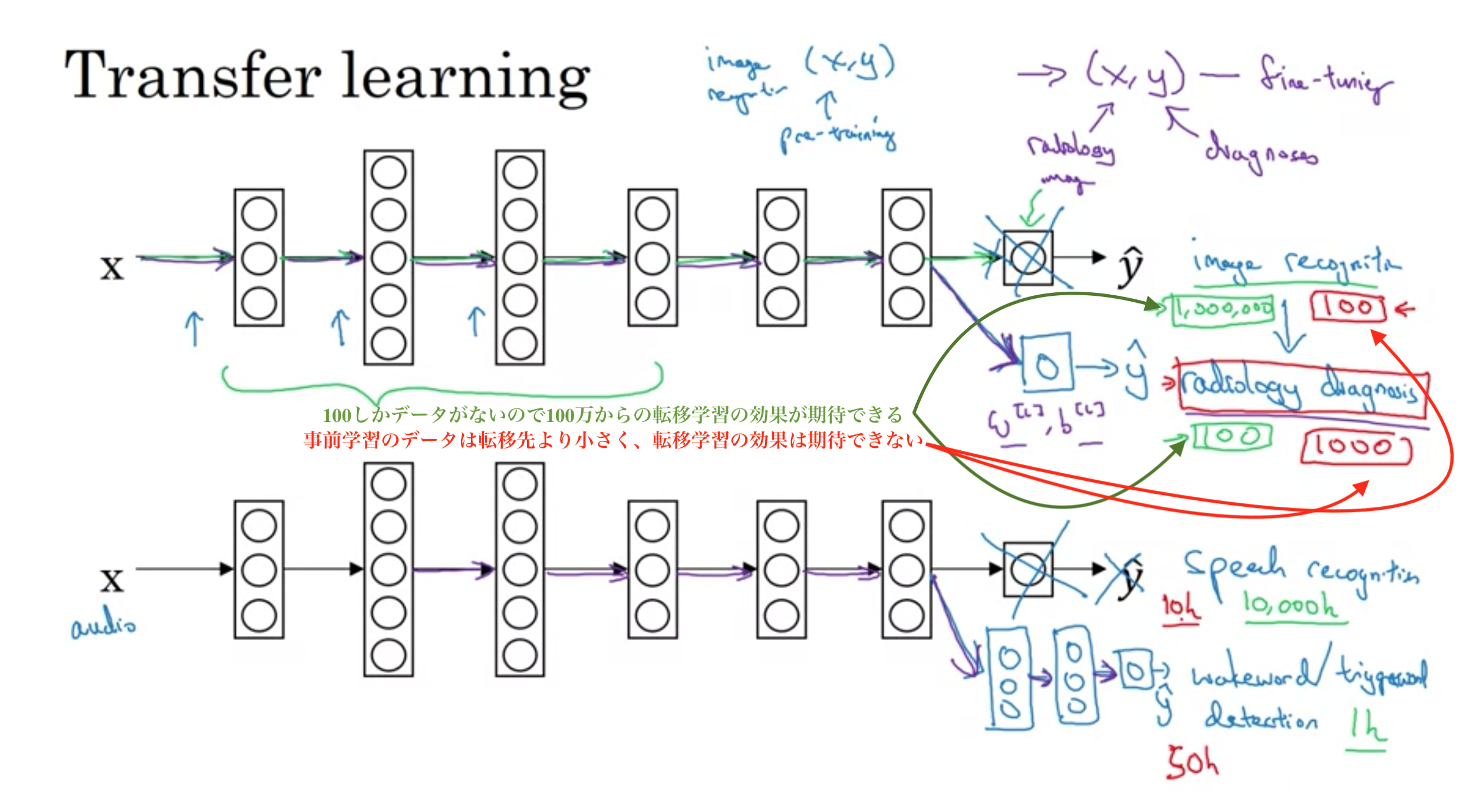 転移学習の例
転移学習の例
転移学習が理にかなっている条件
・転移元と転移先が同じ入力xになっている
(例: 画像分類から放射線検査の転移学習=>入力が画像,
音声認識からウェイクワード/トリガー検出(Hey Siri, OK google など)=>入力がオーディオ)
・転移先より転移元が多くのデータを持っている
マルチタスク学習とは単一のモデルで複数の課題を解く機械学習の手法。 関連する複数の課題を同時に学習させることで、課題間の共通の要因を獲得し、課題の予測精度を向上させます。
 自動運転の簡素化
自動運転の簡素化
歩行者、車、一時停止標識、信号の4つのタスクを同時に行う
最初のトレーニングの例として、ラベラーが歩行者がいて車はない、と言ったが、一時停止の標識があるかどうか、または信号機があるかどうかにラベルを付けなかったとする。
一部の画像に一部のオブジェクトのみしかラベルを付けられていない場合でもマルチタスク学習は機能する。
ラベルの一部が疑問符または実際にラベル付けされていない場合でも、1から4までのjの合計では、0または1のラベルを持つjの値のみを合計する。
したがって、疑問符があるときはいつでも、その項を合計から省略し、ラベルがある値のみを合計し、これにより、このようなデータセットも使用できるようになります。
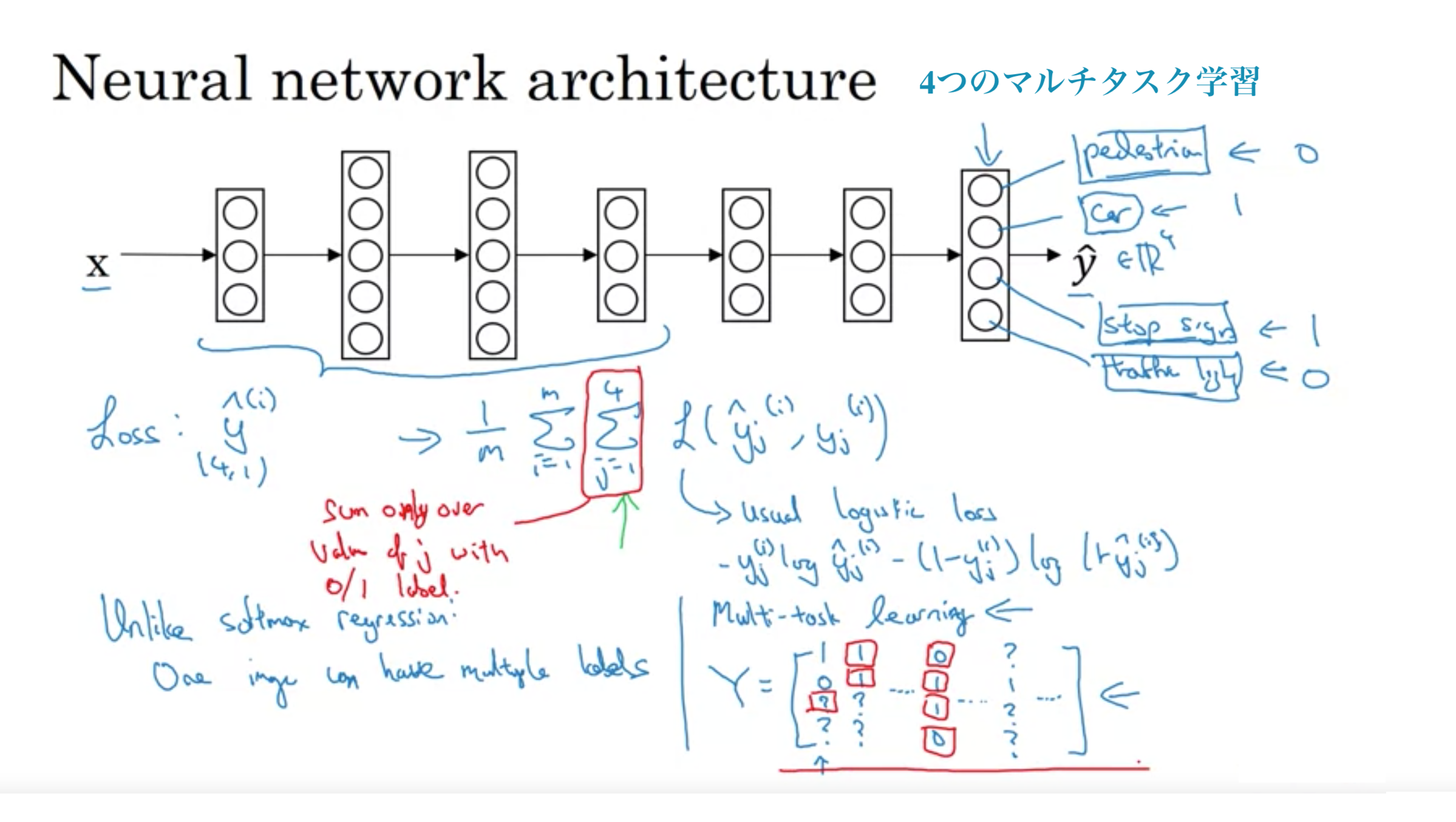
マルチタスク学習が理にかなっているとき
・低レベルの特徴を共有することで課題間の共通の要因を獲得し、予測精度を向上させうる一連のタスクについてトレーニングする場合
(自動運転の例では、信号機や車、歩行者の認識には、一時停止標識の認識にも役立つ類似した特徴があることは理にかなっている。これらはすべて道路の機能であるため。)
・成功した多くのマルチタスク設定を見るに、それぞれのタスクで所有するデータ量はかなり似ていることが多い
(これは常に正しいとは限らない)
・全てのタスクで、良く機能するに十分な大きさのニューラルネットワークを訓練することができる
要約
マルチタスク学習は、多くのタスクを実行する1つのニューラルネットワークを訓練することを可能にし、独立してタスクを実行するよりも良いパフォーマンスを発揮する。
複数の処理段階を必要とするデータ処理システムまたは学習システムがいくつかある。そして、エンドツーエンドのディープラーニングが行うことは、それらすべての複数の段階を実行し、通常は単一のニューラルネットワークに置き換えることができるということ。
音声認識の例 入力Xがオーディオ、Yが筆記録
処理段階
1. XからMFCC(人の聴覚特性に合わせて音素を変換しスペクトル外形を表現)により特徴を抽出
2. 抽出した低レベルの特徴から機械学習アルゴリズムを適用して、オーディオクリップ内の音素を見つける
3. 音素をつないで個々の単語を形成し、それらをつないでオーディのクリップのトランスクリプト(筆記録)を形成
End-to-End deep learning の場合 ニューラルネットワークが全て実行
オーディオ->トランスクリプト(筆記録)
End-to-End deep learningは多くのデータが必要
小さいデータセット(3000時間のオーディオデータ)でトレーニングしている時、従来のパイプラインが非常にうまく機能する
非常に大きなデータセット(例えば10,000~100,000時間)がある場合にのみ、エンドツーエンドのアプローチが非常に良く機能し始める。
中程度のデータがある場合は、音声を入力して特徴を経由し、ニューラルネットワークの音素を出力することを学習する中間的な方法もある。
回転式改札による例
カメラが、人が近づくのを認識したら自動で回転式改札が人を通す
アプローチは2段階
1. カメラの画像から、人の顔を認識して切り取り、拡大する
2. 切り取った顔から誰なのか予測する
なぜ2段階のアプローチを取るのか?理由は2つ
1. 解決しているアプローチの2つは実際にかなりシンプルである
2. 2つのサブタスクのそれぞれに大量のデータがある
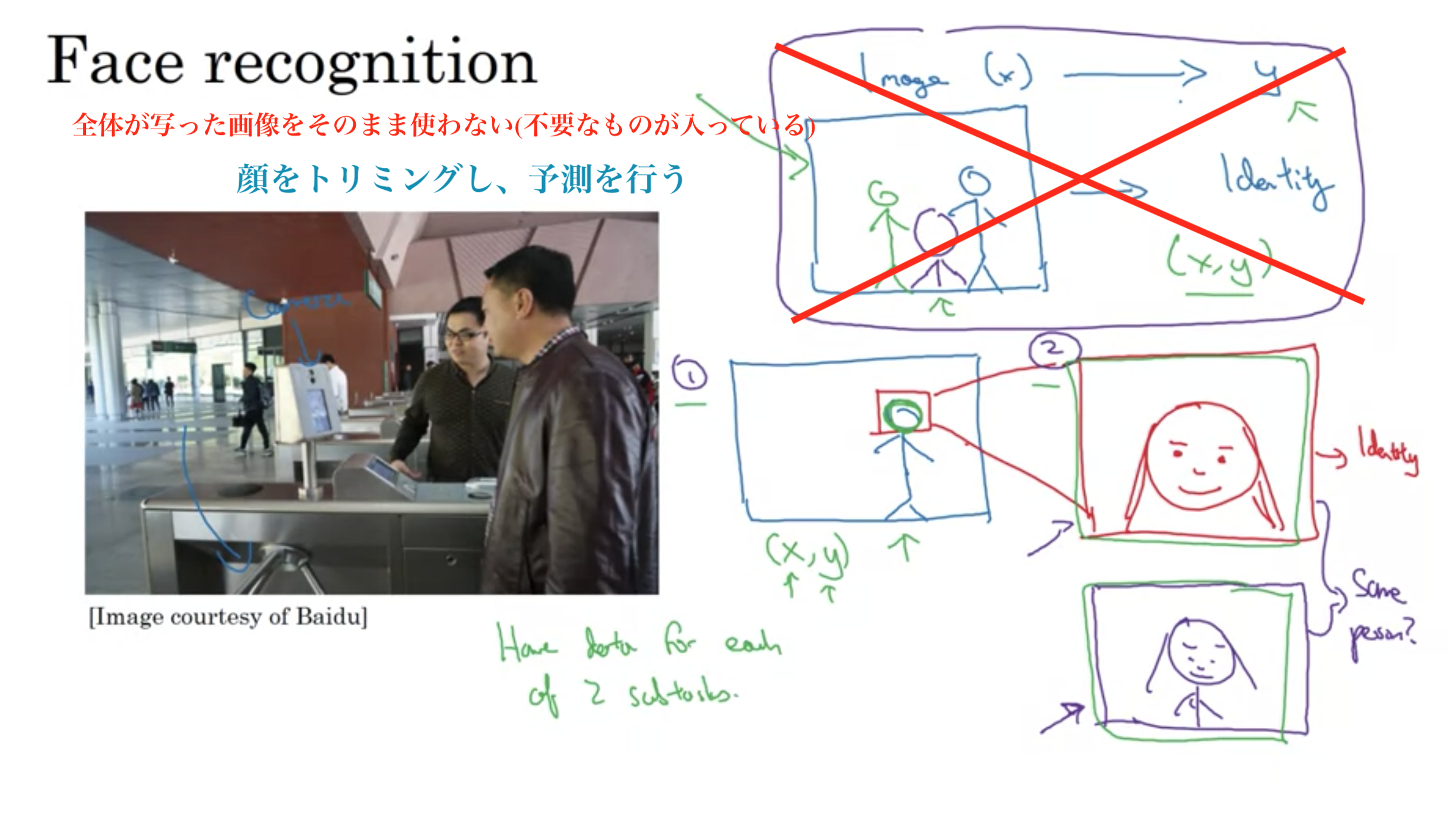 回転式改札の顔認識
回転式改札の顔認識
機械翻訳
英語=>テキスト分析=>...=>French
エンドツーエンドの場合 英語=======>French
子供の年齢予測
画像=>骨のレントゲン=>年齢
エンドツーエンドの場合 画像==>年齢
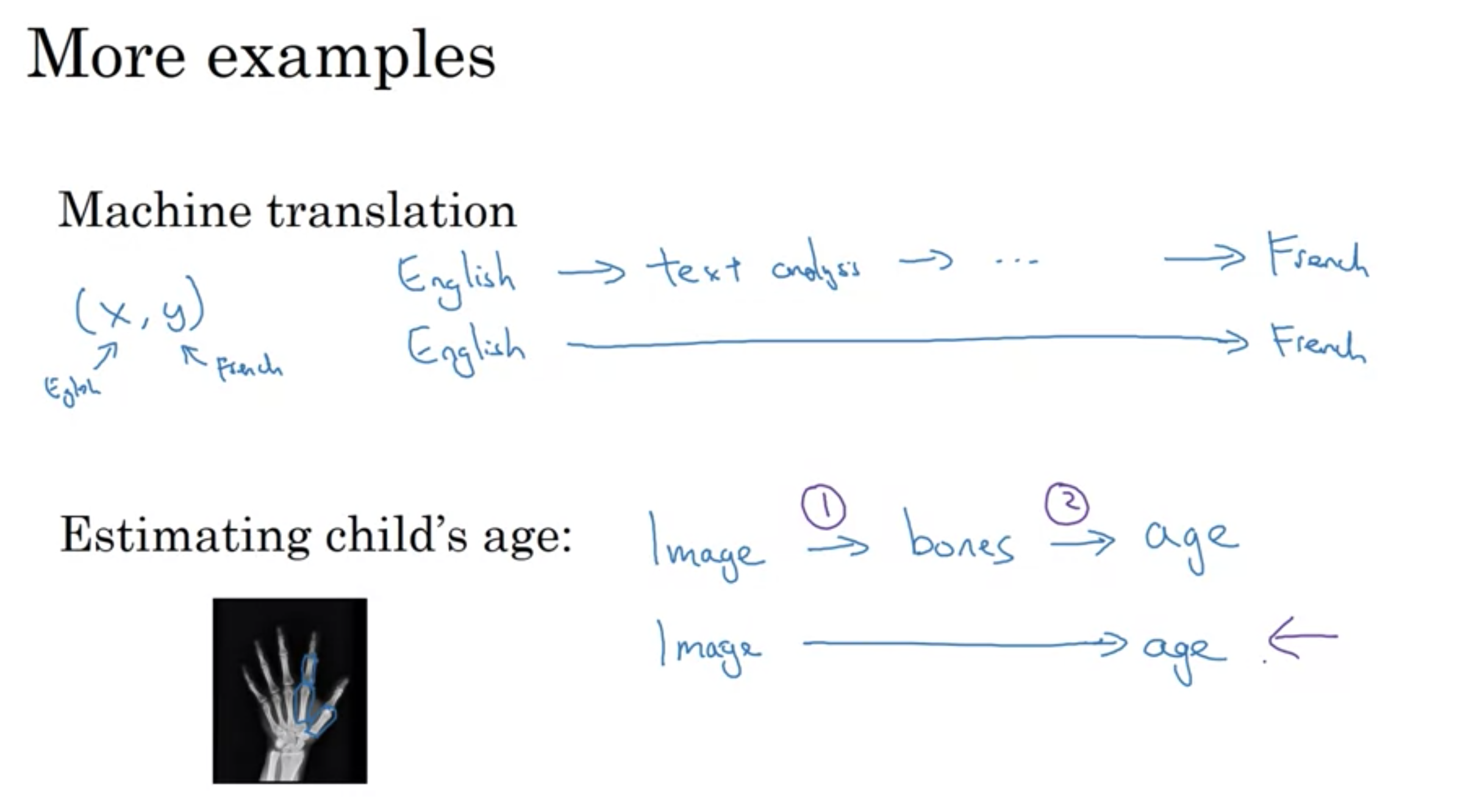 エンドツーエンドのその他の例
エンドツーエンドのその他の例
要約
エンドツーエンドは非常にうまく機能し、システムを本当に簡素化することができ、それほど多くの手動設計された個々のアプローチを構築する必要がない。しかし、万能薬ではなく、データが不十分などの理由で常に機能するとは限りません。次の章では、いつ、エンドツーエンドのディープラーニングを使用すべきでないか、そしてこれらの複雑な機械学習システムを組み合わせる方法について、より体系的な説明を共有。
end to end の長所と短所
長所
・データに語らせるだけ
(ニューラルネットワークが自動で特徴を抽出し、予測を行う)
・必要なコンポーネントの手動設計が少ない
(設計ワークフローを簡略化し、多くの時間を費やして機能を設計したり、これらの中間表現を手動で設計したりする必要はない)
短所
・潜在的に有用な手動のワークフローを除外する
(そのため、機械学習の研究者は、手作業で物事を設計することを非難する傾向があるが、手動での設計は訓練セットが小さい場合とても役に立つ)
end to end ディープラーニングの適用
重要な質問: XからYへのマッピングに必要な複雑さの関数を学習するのに十分なデータがあるかどうかです。
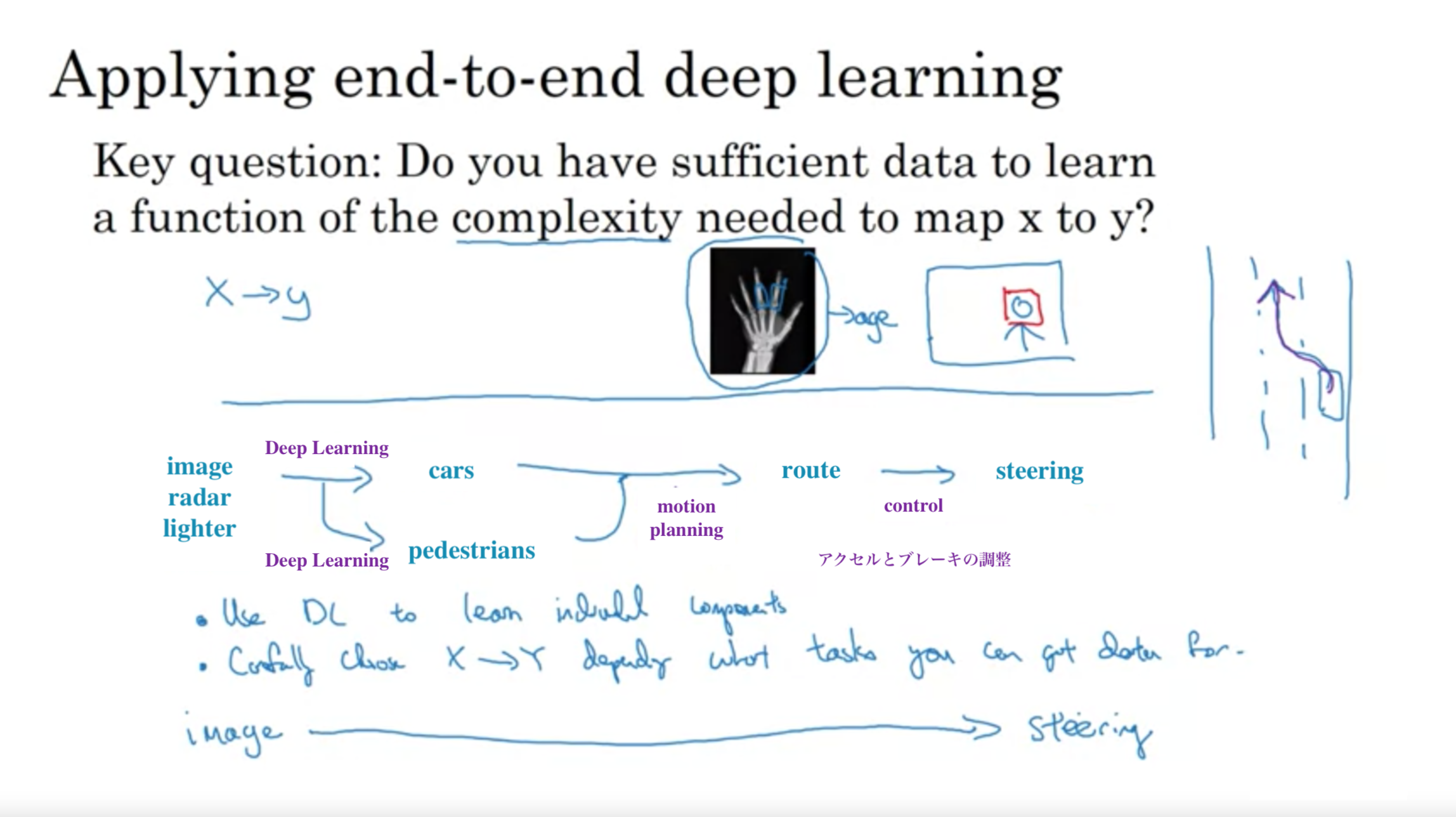 エンドツーエンド ディープラーニングの適用
エンドツーエンド ディープラーニングの適用
この講座では、プログラミングの実装ではなく、ディープラーニングのワークフローや、誤差の解析、データの分布が異なる時の対処法について知ることができます。この知識は、ディープラーニングーを本格実装する前に必ず知っておきたいと思う内容でした。
コースも2週間で完結しますし、技術書からは得られないような知識ばかりだったので、ぜひ興味のある人は受けてみて下さい。
https://www.coursera.org/learn/machine-learning-projects/