Dragon Arrow written by Tatsuya Nakaji, all rights reserved 
updated on 2021-02-23

シーケンスの用語解説 - 順番に並んでいること。または、並んでいる順番で処理を行うこと
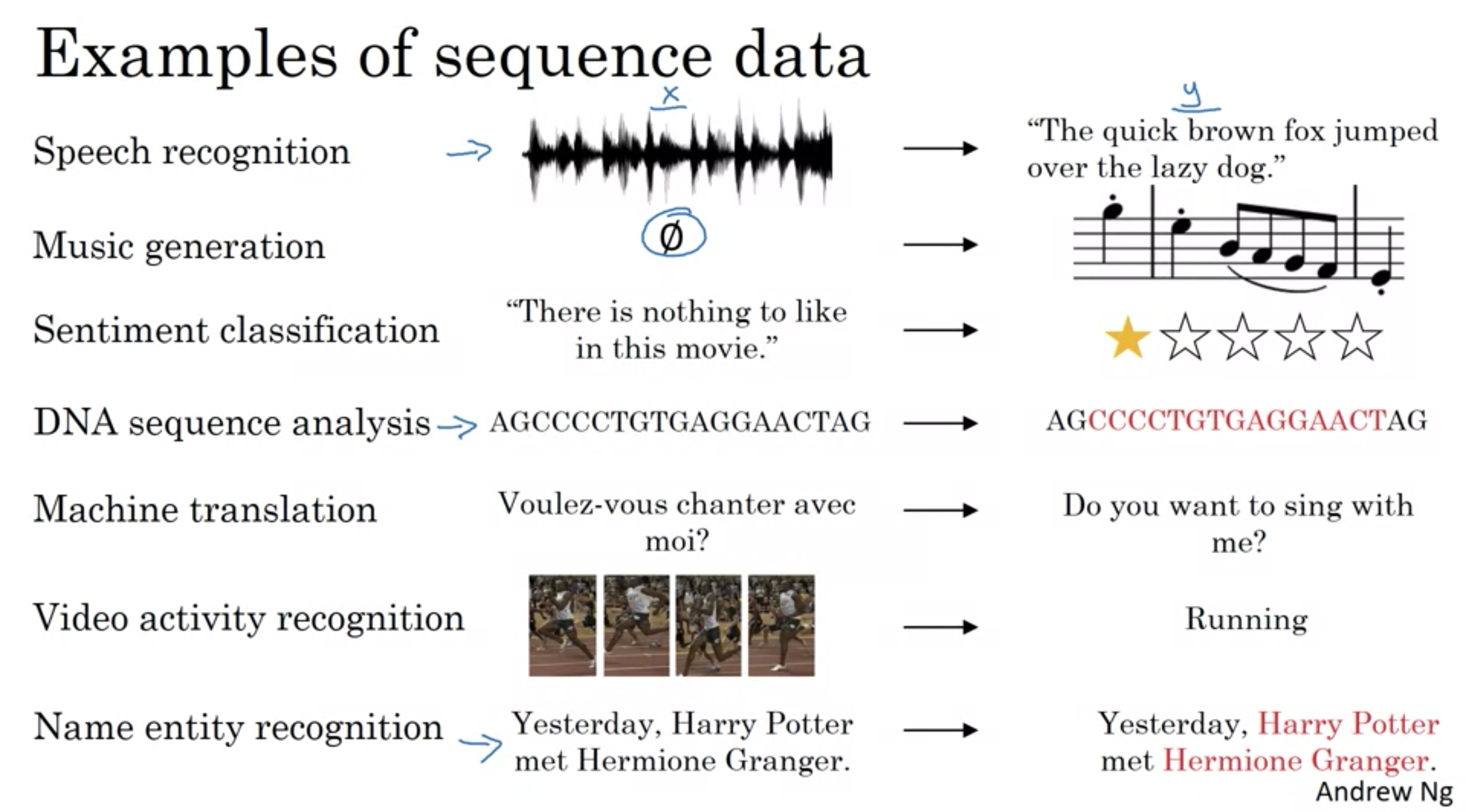 シーケンスデータの例
シーケンスデータの例
音声認識
- 音声クリップ(入力X)が与えられ、それをテキスト(出力Y)に起こすことが求められる
- インプットとアウトプットがシーケンスデータ
- 入力(音声クリップ)は時間軸に沿って展開、Y(テキスト)は単語が連なったもの
音楽生成
- アウトプットだけがシーケンス、インプットは空にもなりうるし、1つの整数にもなりうる(生成したい音楽のジャンル、最初の音符の指定など)
感情分類
- インプットの文章がシーケンス、アウトプットはレビュー(星の数)
DNA解析 DNAはアルファベットA,C,G,Tで表現される DNAシーケンスが与えられた時に、どの部分がタンパク質と並びが一致するかラベル付けを行う
AGCCCCTGTGAGGAACTAG -> AGCCCCTGTGAGGAACTAG
機械翻訳
- 文章がインプット 翻訳したものが
動画認識
- 動画の1コマ1コマが与えられ、どんな骨堂をしているか認識
固有表現抽出
- 与えられた文章の中から人物名を特定
上記の問題全ては、教師あり学習として解決できるが、シーケンスデータを扱う問題には多くの種類がある
シーケンスモデルを構築する上で使用する表記法について定義
例
固有表現抽出 (入力の文章から人の名前を判別するシーケンスモデル)
- 入力X: Harry Potter and Hermione Granger invented a new spell (ハリーポッターとハーマイオニーは新しい呪文を発明した)
- 出力Y: 入力の各単語が人名か否かを1(True),0(False)で出力 1 1 0 1 1 0 0 0 (実際はもっと複雑で、名前が姓名がどこからどこまでかも判断しなければならないが、今回はシンプルな例)
入力の9つの単語は\(x^{<1>},x^{<1>},...,x^{<9>}\)で表され、インデックスtにより、\(x^{<1>}\)で表現される。(tの由来はtemporal: 時間的な)
同様に、出力は\(y^{<1>},y^{<1>},...,y^{<9>}\)
訓練データi番目のインデックスtの場合、\(x^{(i)<t>}\)
また、訓練データによって長さが異なるため、i番目の入力長は\(T^{(i)}_{<x>}\)で表され、\(T^{(i)}_{<x>}\)=9
同様に、出力は\(T^{(i)}_{<y>}\)=9
*固有表現抽出はサーチエンジンにも使われる。(例えば、過去24時間のニュースに登場した全ての人を見出し化して、記事を適切に検索できるようにする) 人名、会社名、時間、場所、国、通貨、その他様々な文字抽出に用いられる
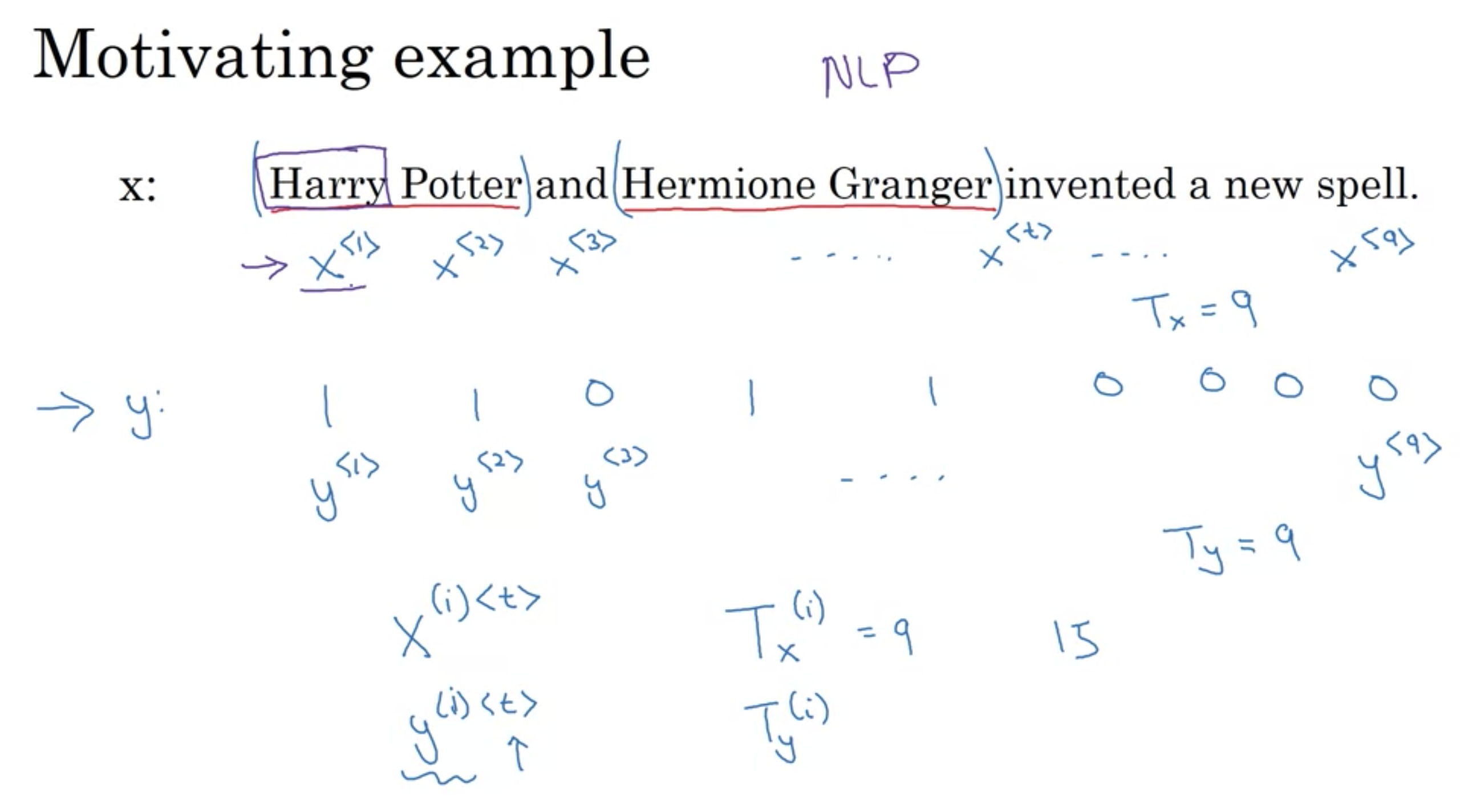 シーケンスモデルでの表記法
シーケンスモデルでの表記法
ボキャブラリーの辞書を用意し、ワンホットエンコーディングで固有名詞を含むかを表示する
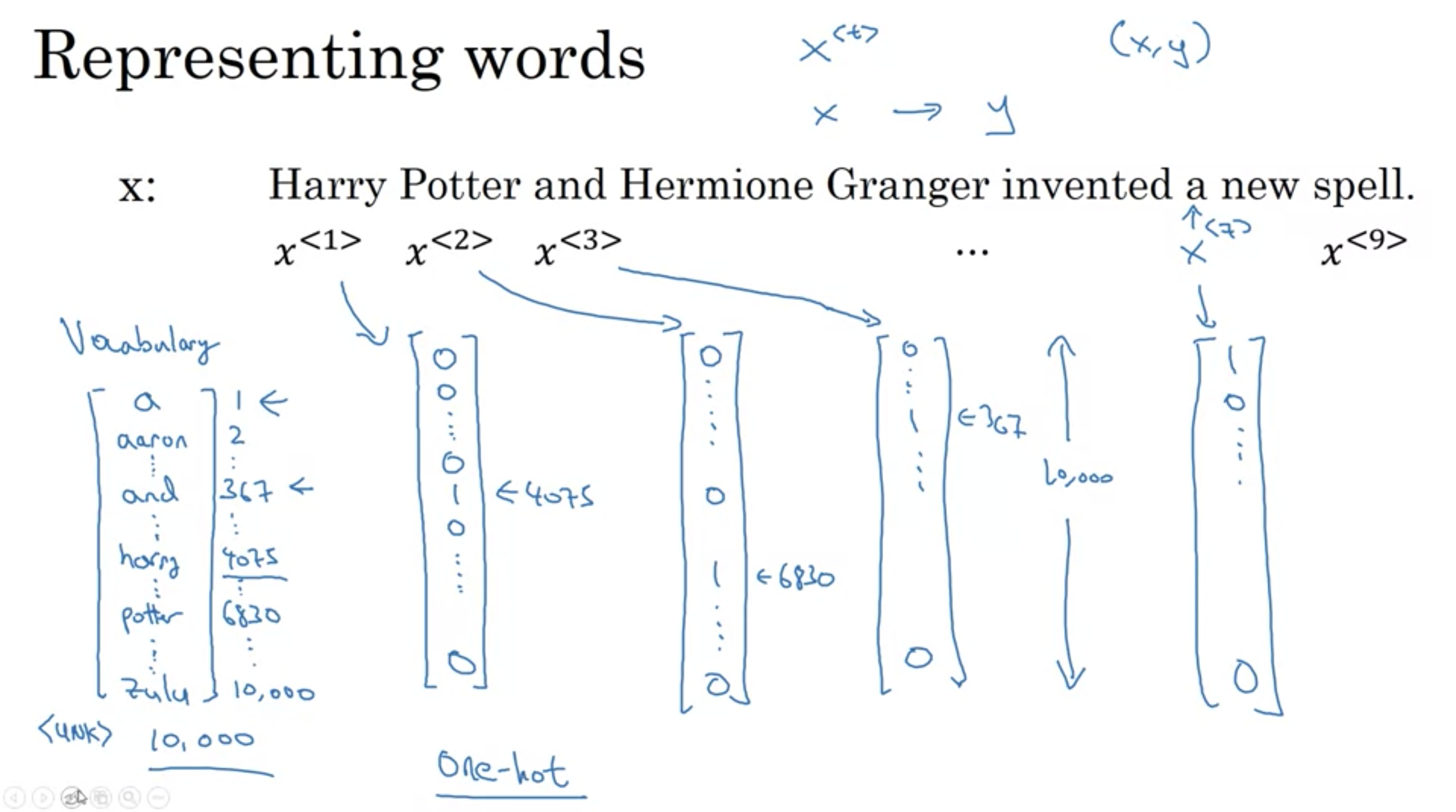
例えば、10,000語を含むボキャブラリーを使用(\(n_x\)=10,000)して、ミニバッチ数が20(m=20)、タイムステップが10(\(T_x\)=10)の場合、入力の次元は(10,000, 20, 10)になる。
各単語を入力としていくつかの隠れ層を通って、最終的には、それぞれの単語で0/1の値が出力される
1. 入力と出力は、データによって長さが異なる可能性がある (入力長と出力長はデータによってバラバラ)
2. このような単純なニューラルネットの構造だと、文の色々な場所で学習した特徴量を共有しない (1番目に登場した単語"Harry"が人名の一部だと学習したならば、他のインデックスで現れた時も人名だと判断してほしいが、それができない)
* CNNは、画像全体をフィルタがスライドするので、特徴がどこにあっても抽出できる(移動不変性または位置不変性) シーケンスモデルにも、同じような効果が欲しい。
...そこで、RNN(再帰型ニューラルネットワーク)が2つの欠点を解決する
RNNの弱点
入力データの内、ある時点での予想は、シーケンス内の早い方の情報しか使わない(後ろの方は使われない)
例えば、以下の分は、前者は人名で、後者は人名ではないが、最初の3文を見ただけでは判断できないもの
He said, "Teddy Roosebelt was a great president."
He saild "Teddy bear are on sale!"
この課題を解決するBRNN (双方向再帰型ニューラルネットワーク)と言うものもある。
 RNN 再帰型ニューラルネットワーク
RNN 再帰型ニューラルネットワーク
活性化関数では、tanhが使われるのが主流(Reluも使われる)で、これによって起きる勾配消失問題については別の対策を行う。
Wax ,Waa ,Wya, ba, by は全ての時点で共有される係数であり、\(g_1\), \(g_2\)は活性化関数である。
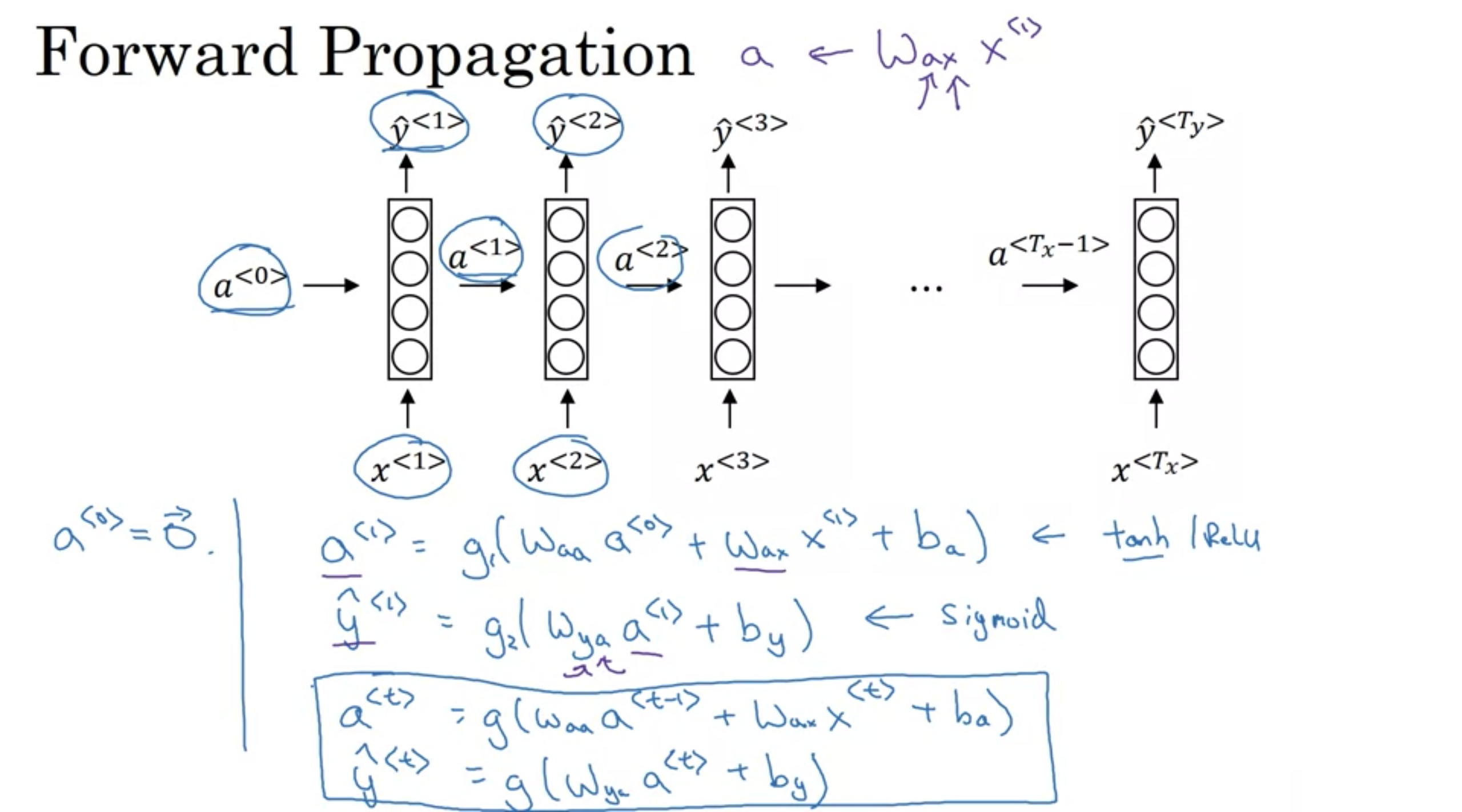 順伝播
順伝播
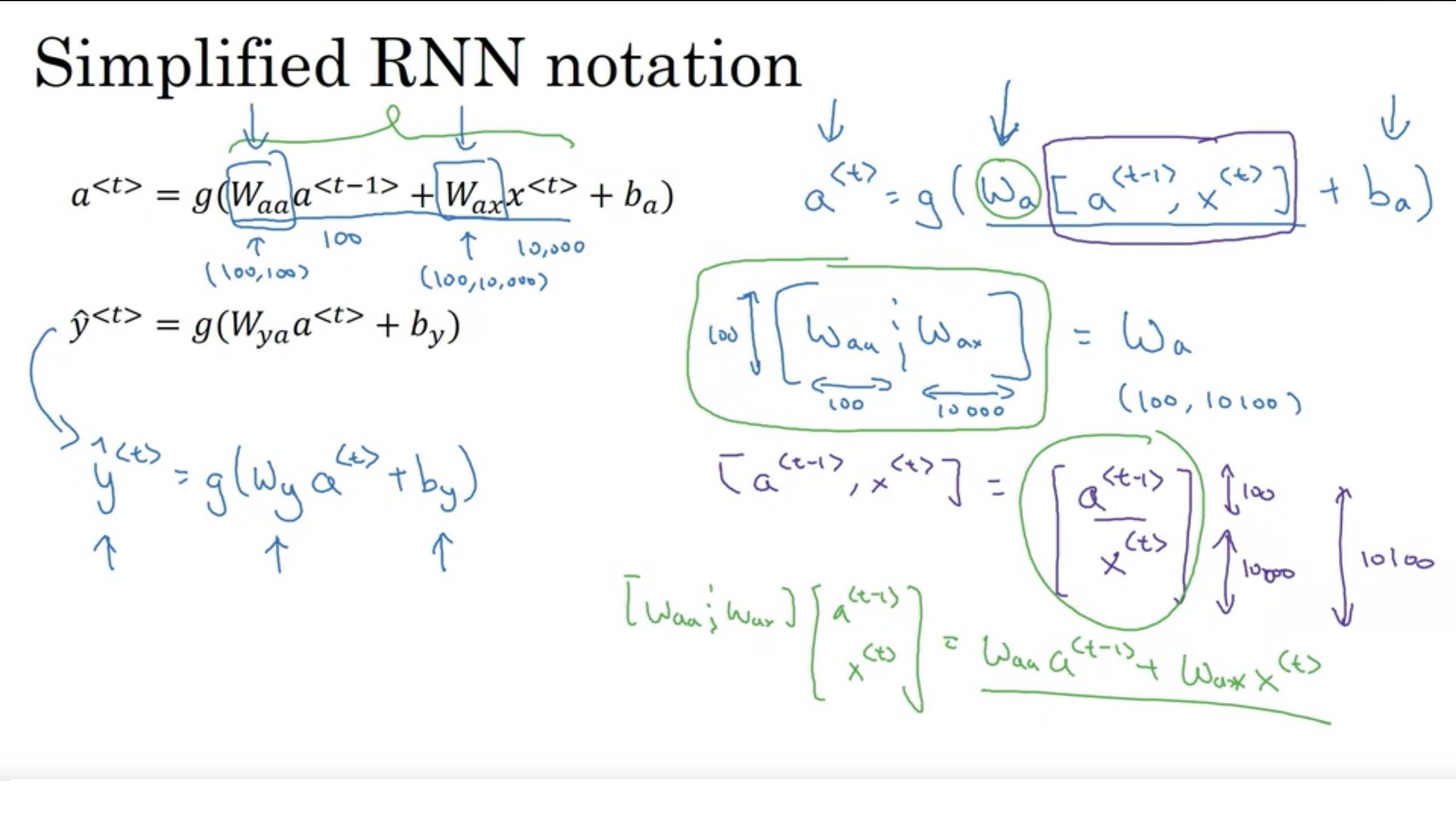 簡易化したRNNの表記
簡易化したRNNの表記
文章の単語が人の名前かそうじゃないかは、2値分類なので、交差エントロピー誤差を使用できる
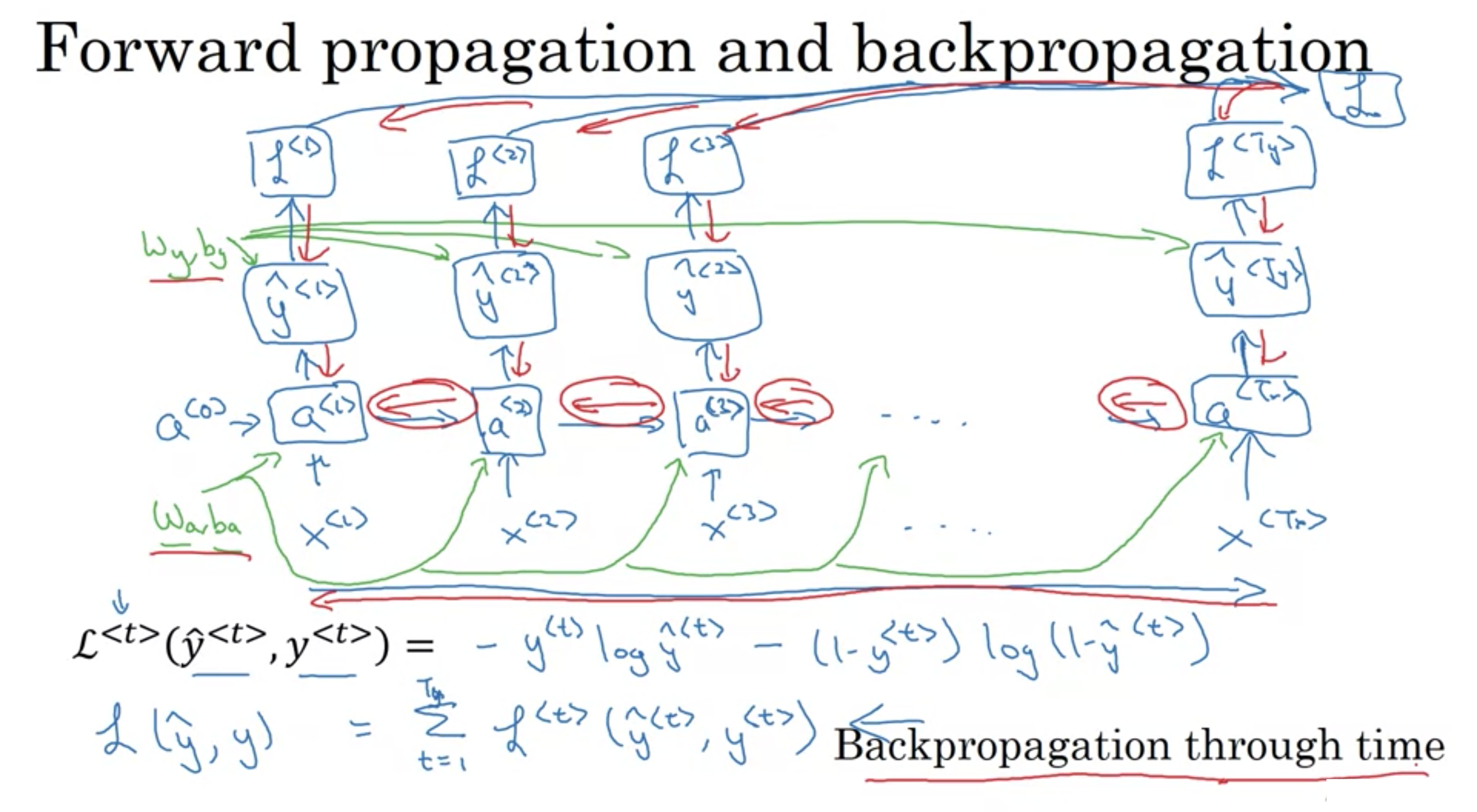 RNN 順伝播と逆伝播
RNN 順伝播と逆伝播
RNNの構造 \(T_{<x>}とT_{<y>}の関係\)
・多対多 (many-to-many)
- 例: 固有抽出表現、機械翻訳
・多対一 (many-to-one)
- 例: 感情分析(映画の感想から星の数を推測)
・一対一 (one-to-one)
- 例: 標準的な普通のニューラールネットワーク
・一対多 (one-to-many)
- 例: 音楽生成
・多対一
・入力: テキスト
・出力: 星の数(0~5)
- 毎回のタイムステップで出力を行うのではなく、RNNは文章全体をまとめて読み込み、出力は最後のタイムステップのみとなる
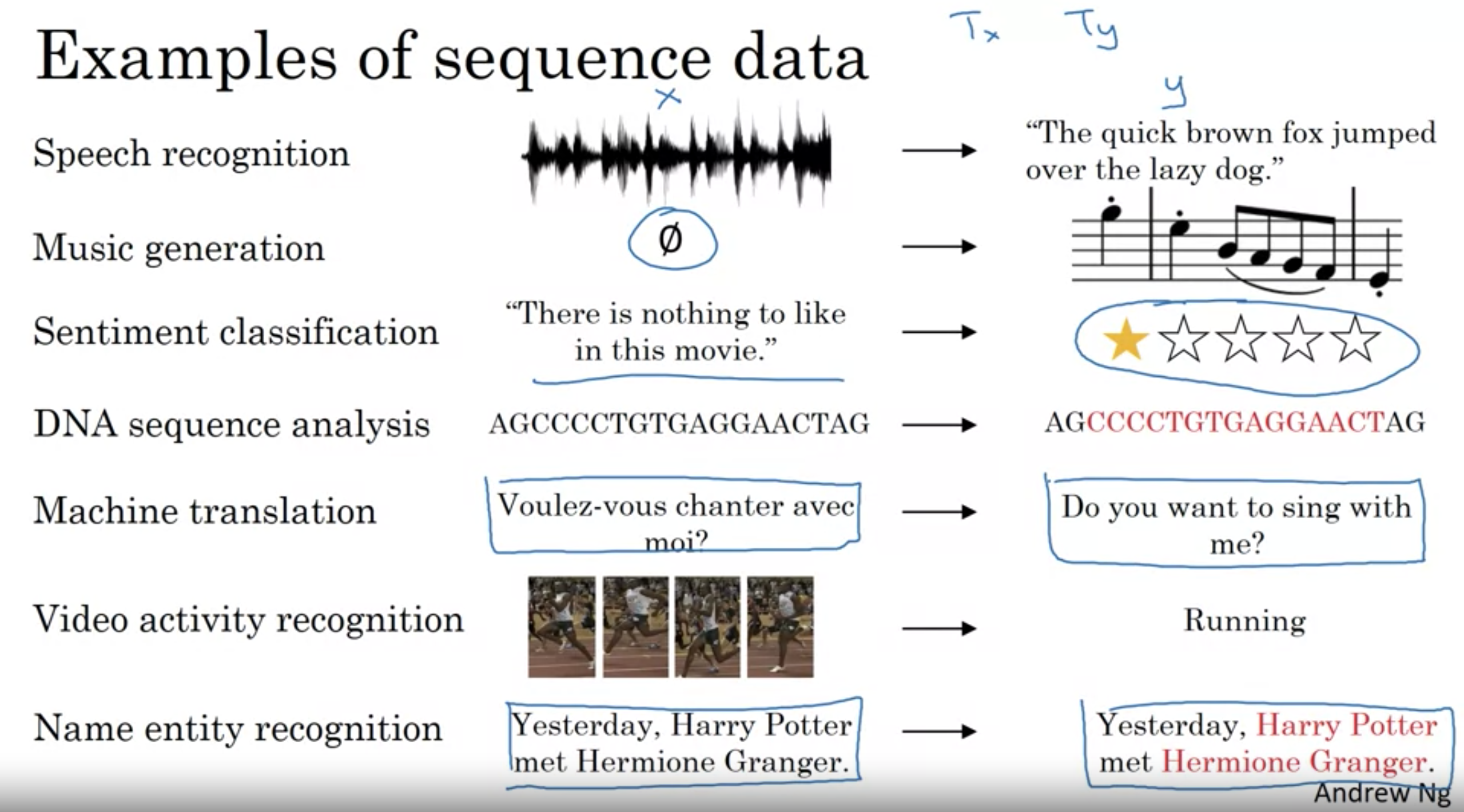 シーケンスデータの例
シーケンスデータの例
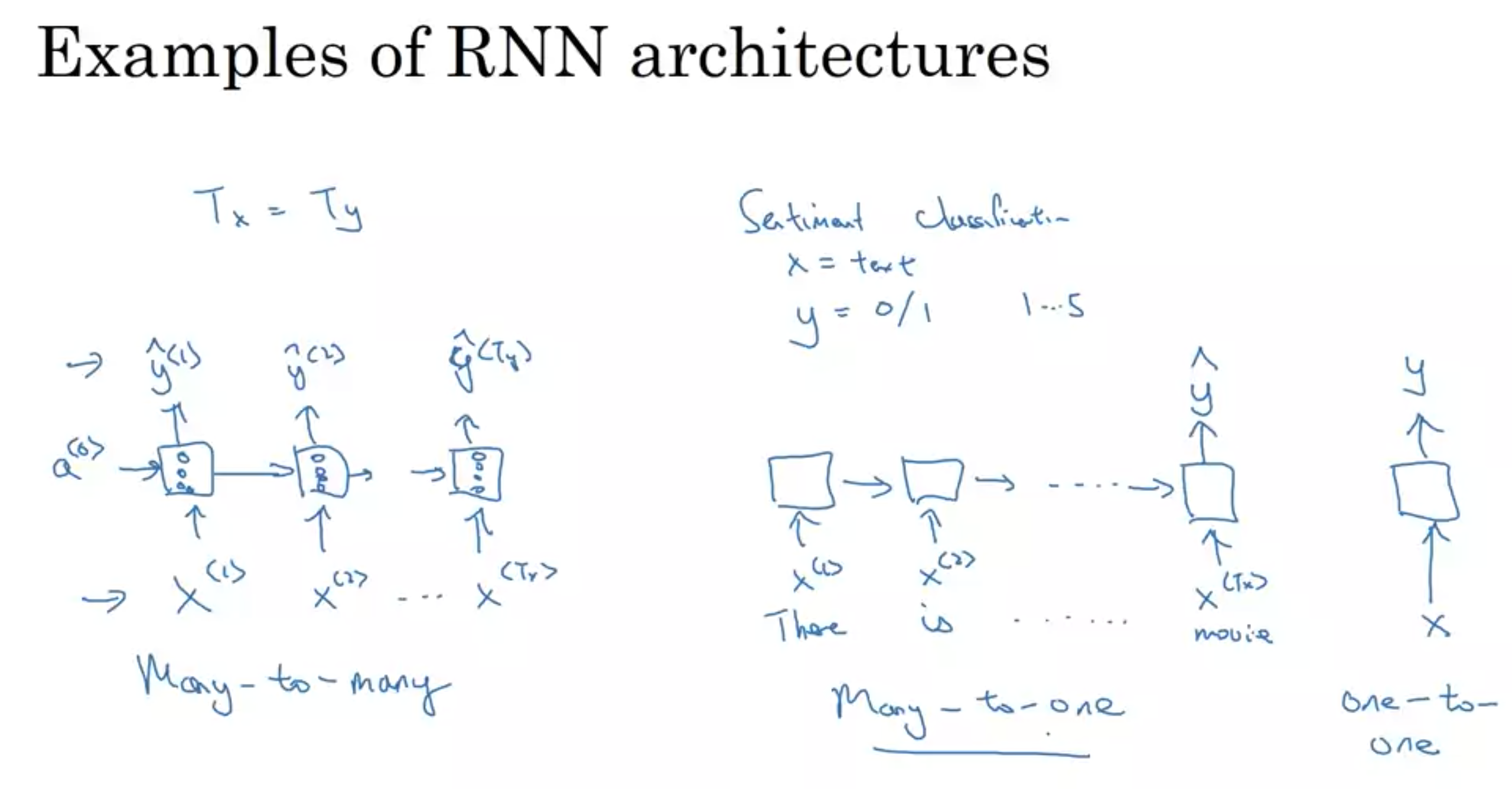 RNNの構造の種類
RNNの構造の種類
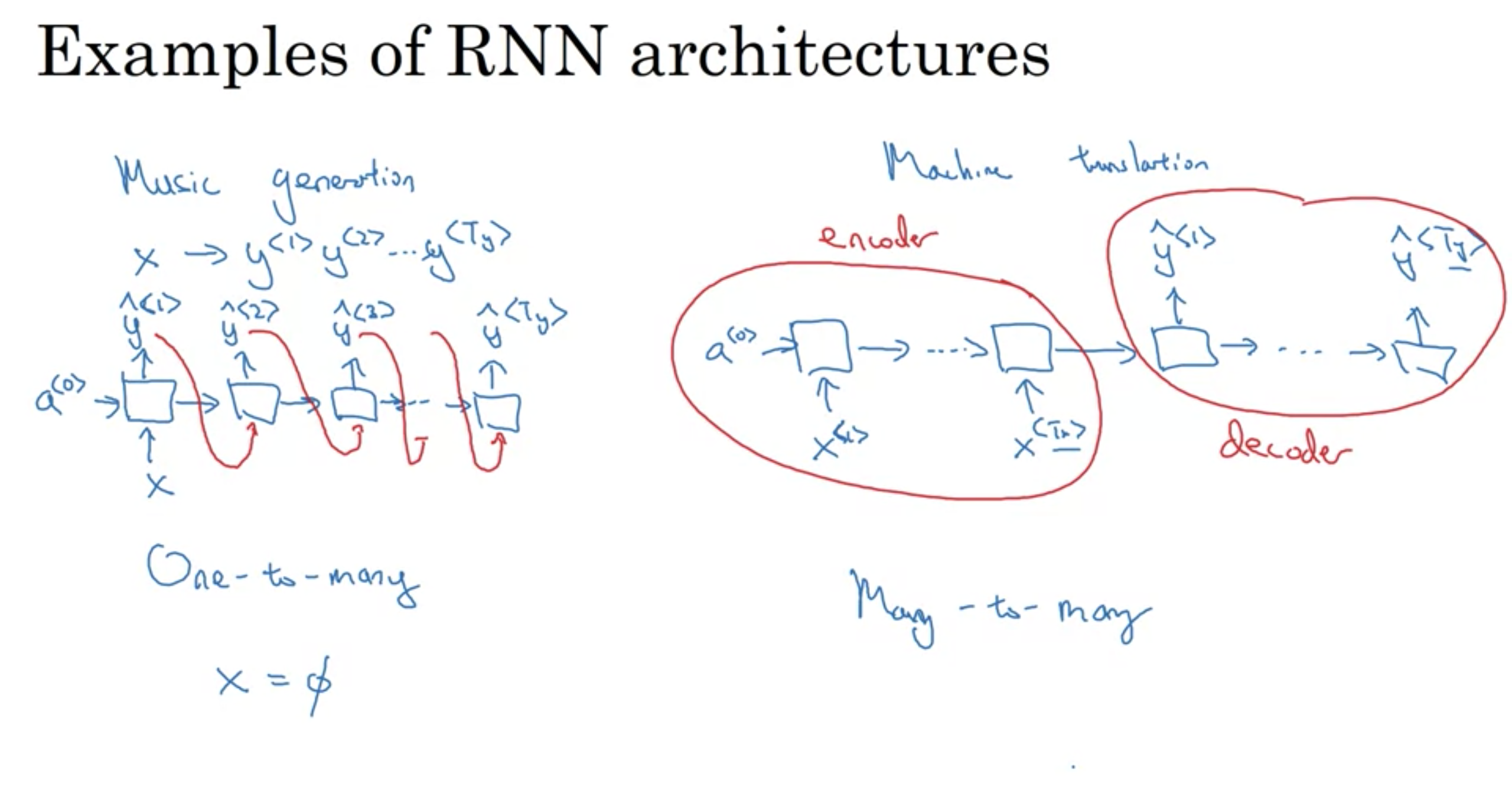 音楽生成と機械翻訳
音楽生成と機械翻訳
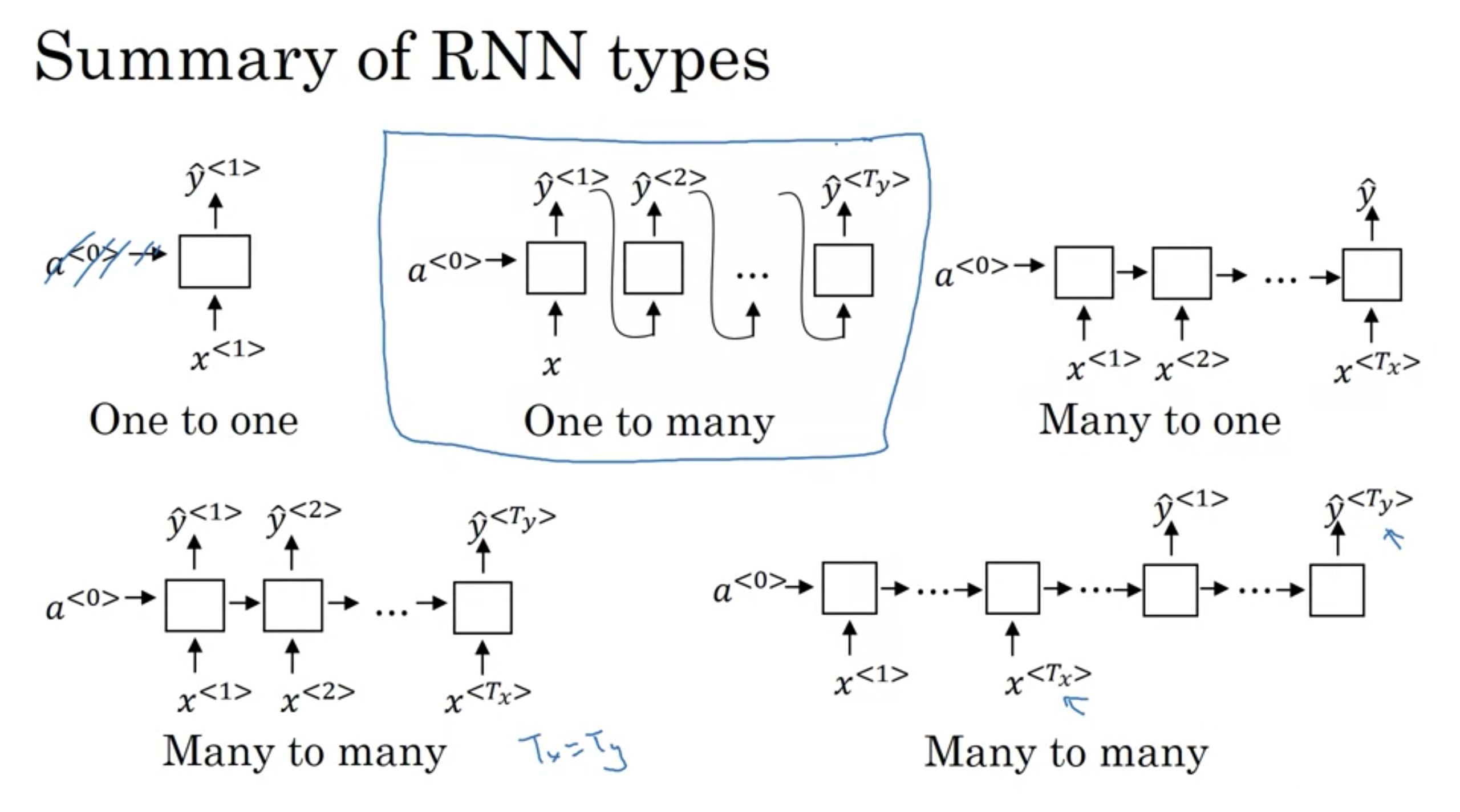 RNNの構造の種類のまとめ
RNNの構造の種類のまとめ
言語モデルとは、単語列に対する確率分布である。長さmの単語列が与えられたとき、単語列全体に対しての確率\({\displaystyle P(y^{<1>},\ldots ,y^{<m>})}\)を与える。 言語モデルを用いると異なるフレーズに対して相対的な尤度を求めることができるため、自然言語処理の分野で広く使われている。 言語モデルは音声認識、機械翻訳、品詞推定、構文解析、手書き文字認識、情報検索などに利用されている。

言語モデル
1万~100万あるいは、それ以上のボキャブラリー辞書を用意し、それぞれの単語ごとに予測される単語の確率を出力する。
 RNNによる言語モデル
RNNによる言語モデル
条件付き確率(じょうけんつきかくりつ、英: conditional probability)は、ある事象 B が起こるという条件下での別の事象 A の確率のことをいう。しばしば「B が起こったときの A の(条件付き)確率」「条件 B の下での A の確率」などと表現される。
\({\displaystyle \operatorname {P} (A\mid B)={\frac {\operatorname {P} (A\cap B)}{\operatorname {P} (B)}}}\)
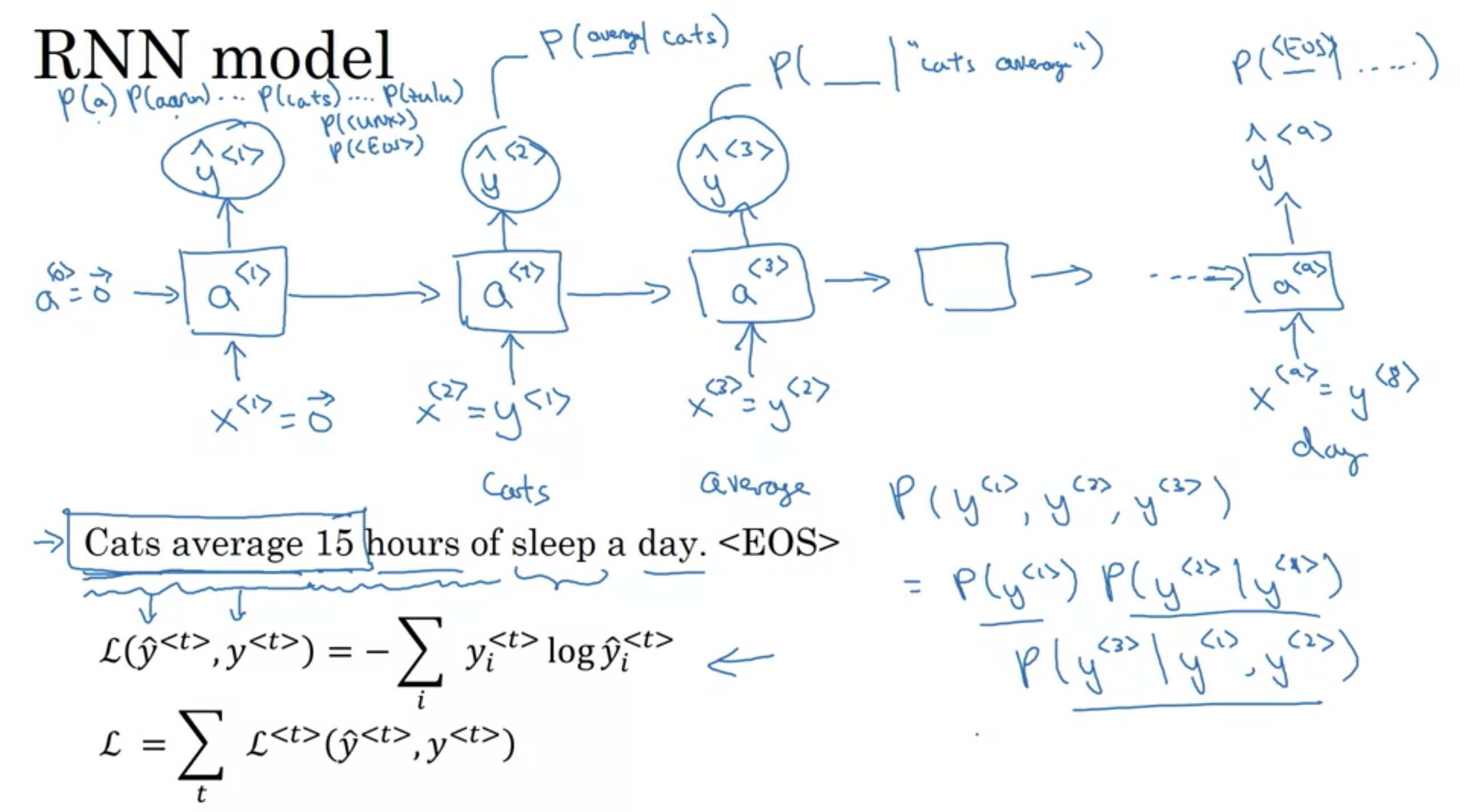 RNN model
RNN model
言語モデルは、連続した言葉の中で、直前の言葉を利用して次の言葉の出現確率を予測することができる。どのくらいの頻度で文章が現れるのかを測ることができるため、機械翻訳に活用されています。次の言葉を予測できることのもう一つ良いことは、アウトプットの確率からサンプリングすることで新しい文章を生成できるGenerativeモデルを得られる点です。そのため、学習用データ次第で様々なものを生成することができます。言語モデルでは、インプットデータは連続的な言葉の列です。そして、アウトプットは予測された言葉の列になります。ネットワークを学習させる時、tステップのアウトプットを次の言葉にしたいため、\(o_tt=x_{t+1}\)とします。
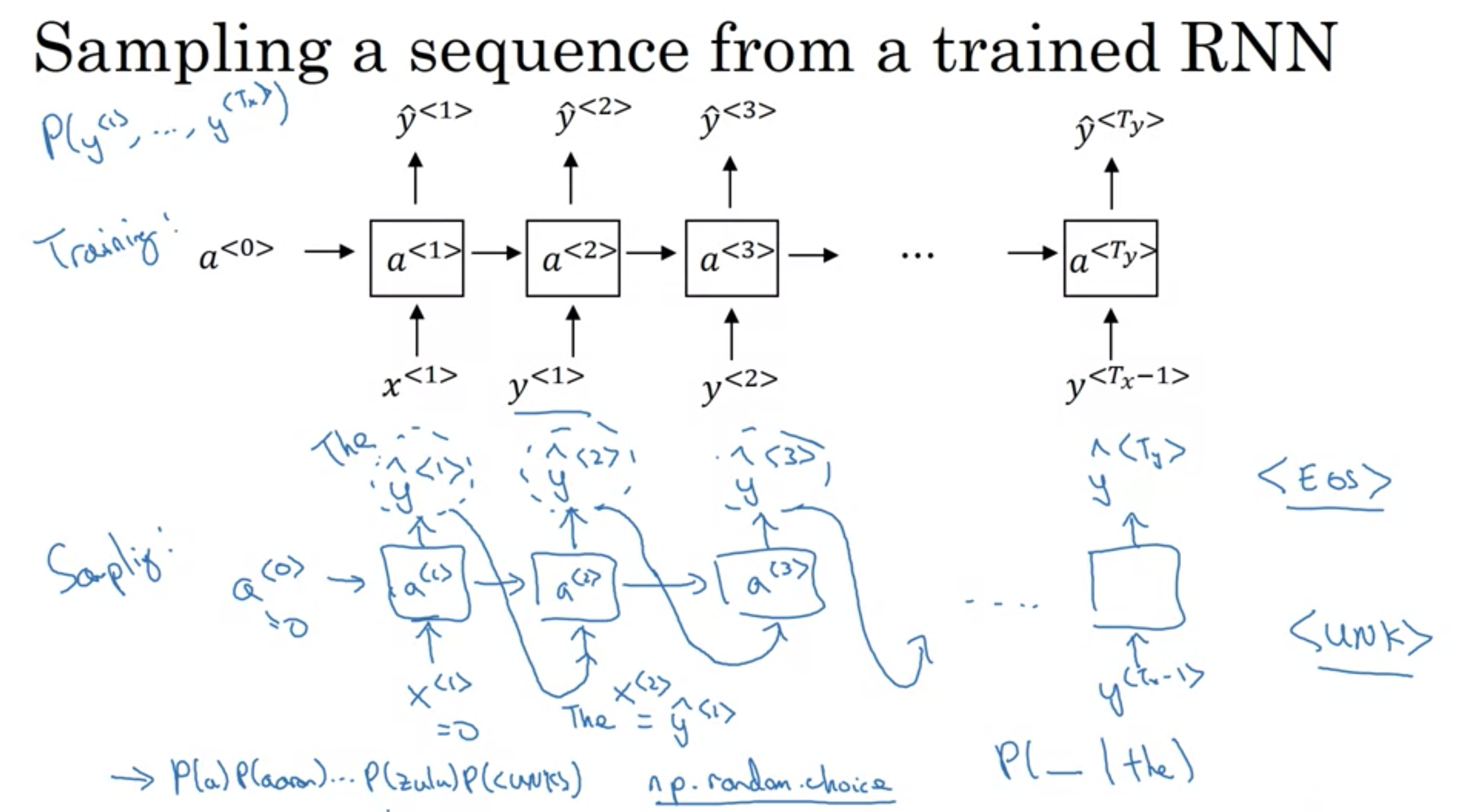 訓練されたRNNからシーケンスのサンプリング
訓練されたRNNからシーケンスのサンプリング
以下の左側の文章は、シェイクスピアのテキストで訓練されたモデルが生成したもので、それはシェイクスピアが書いたみたいに聞こえるものを生成します。
 シーケンス生成
シーケンス生成
勾配消失と勾配爆発について - 勾配消失と勾配爆発の現象は、RNNでよく見られる。これらの現象が起こる理由は、掛け算の勾配が層の数に対して指数関数的に減少/増加する可能性があるため、長期の依存関係を捉えるのが難しいから。
勾配クリッピング - 誤差逆伝播法を実行するときに時折発生する勾配爆発問題に対処するために使用される手法。勾配の上限値を定義することで、実際にこの現象が抑制される。
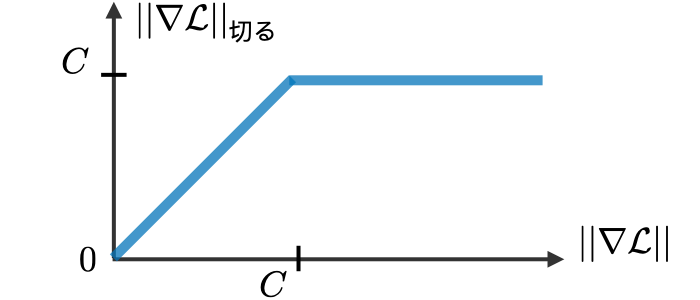
・勾配爆発に堅牢な解決策
- 勾配クリッピング
勾配消失
- GRUを使う、のちに解説
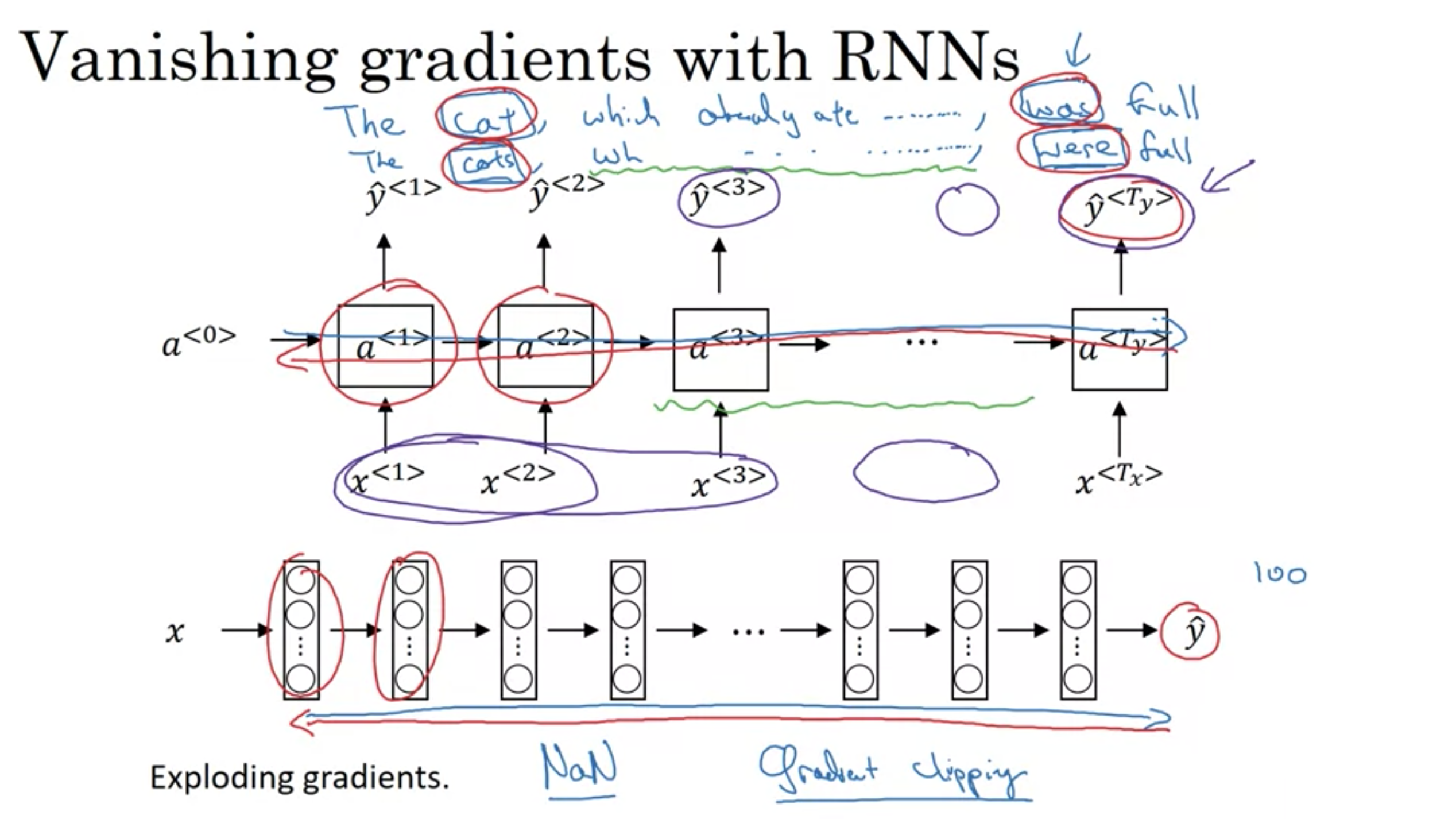 RNNの勾配消失
RNNの勾配消失
ゲート付き回帰型ユニット wiki
2014年にKyunghyun Cho(조 경현)らによって発表された、回帰型ニューラルネットワーク(RNN)におけるゲート機構
ゲートの種類 - 勾配消失問題を解決するために、特定のゲートがいくつかのRNNで使用され、通常明確に定義された目的を持っている。それらは通常\(\Gamma \)と記され、以下のように定義される。
\(\Gamma = \sigma(Wx^{<t>}+Ua^{<t-1>}+b)\)
ここで、W, U, bはゲート固有の係数、σはシグモイド関数です。主なものは以下の表にまとめられている。
| ゲートの種類 | 役割 | 下記で使用される |
| 更新ゲート \(\Gamma_u\) | 過去情報はどのくらい重要ですか? | GRU, LSTM |
| 関連ゲート \(\Gamma_r\) | 前の情報を削除しますか? | GRU, LSTM |
| 忘却ゲート \(\Gamma_f\) | セルを消去しますか?しませんか? | LSTM |
| 出力ゲート \(\Gamma_o\) | セルをどのくらい見せますか? | LSTM |
GRU/LSTM - ゲート付きリカレントユニット(GRU)およびロングショートタームメモリユニット(LSTM)は、従来のRNNが直面した勾配消失問題を解決しようとする。LSTMはGRUを一般化したもの。以下は、各アーキテクチャを特徴づける式をまとめた表。
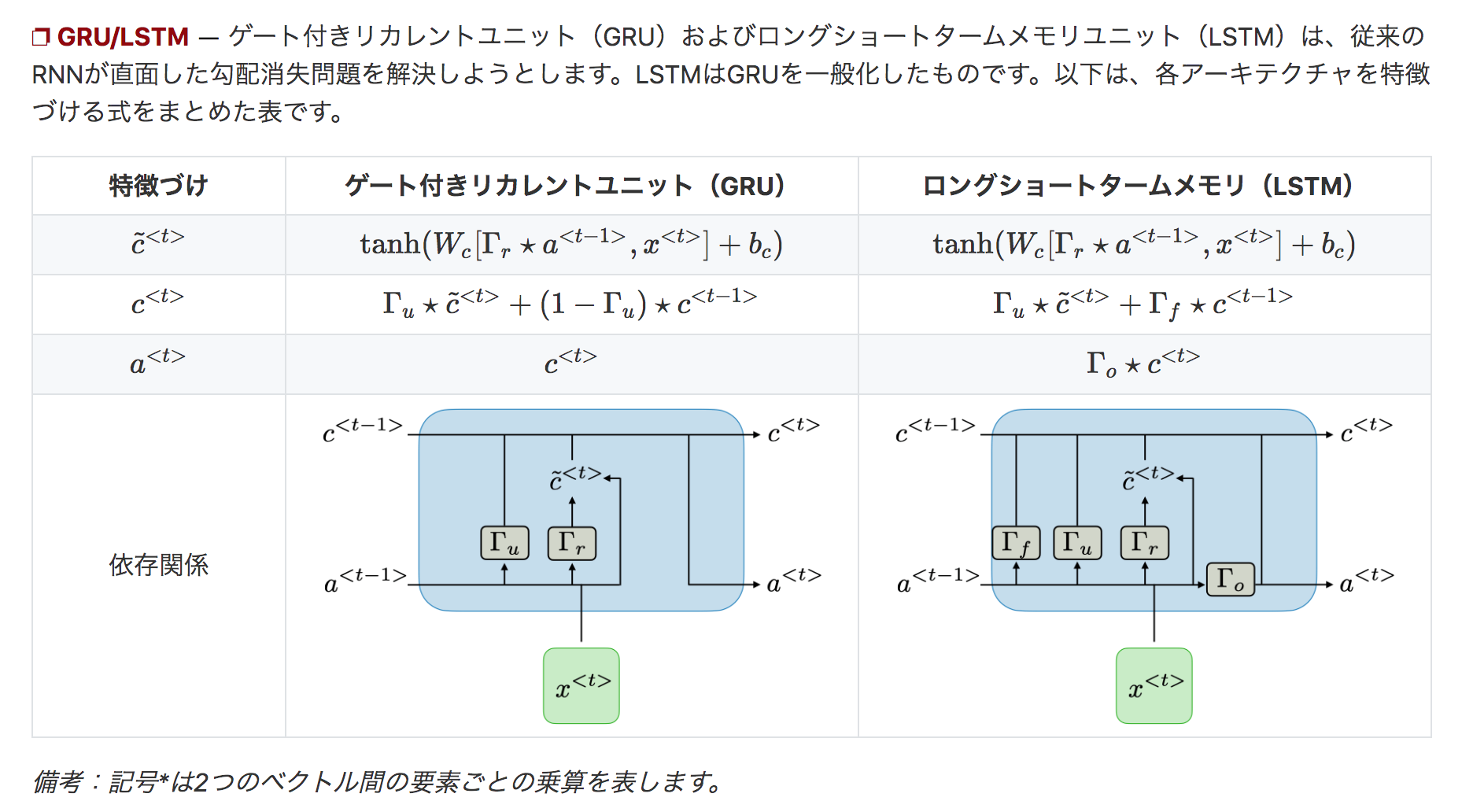
以下サイトから引用 [https://stanford.edu/~shervine/l/ja/teaching/cs-230/cheatsheet-recurrent-neural-networks]
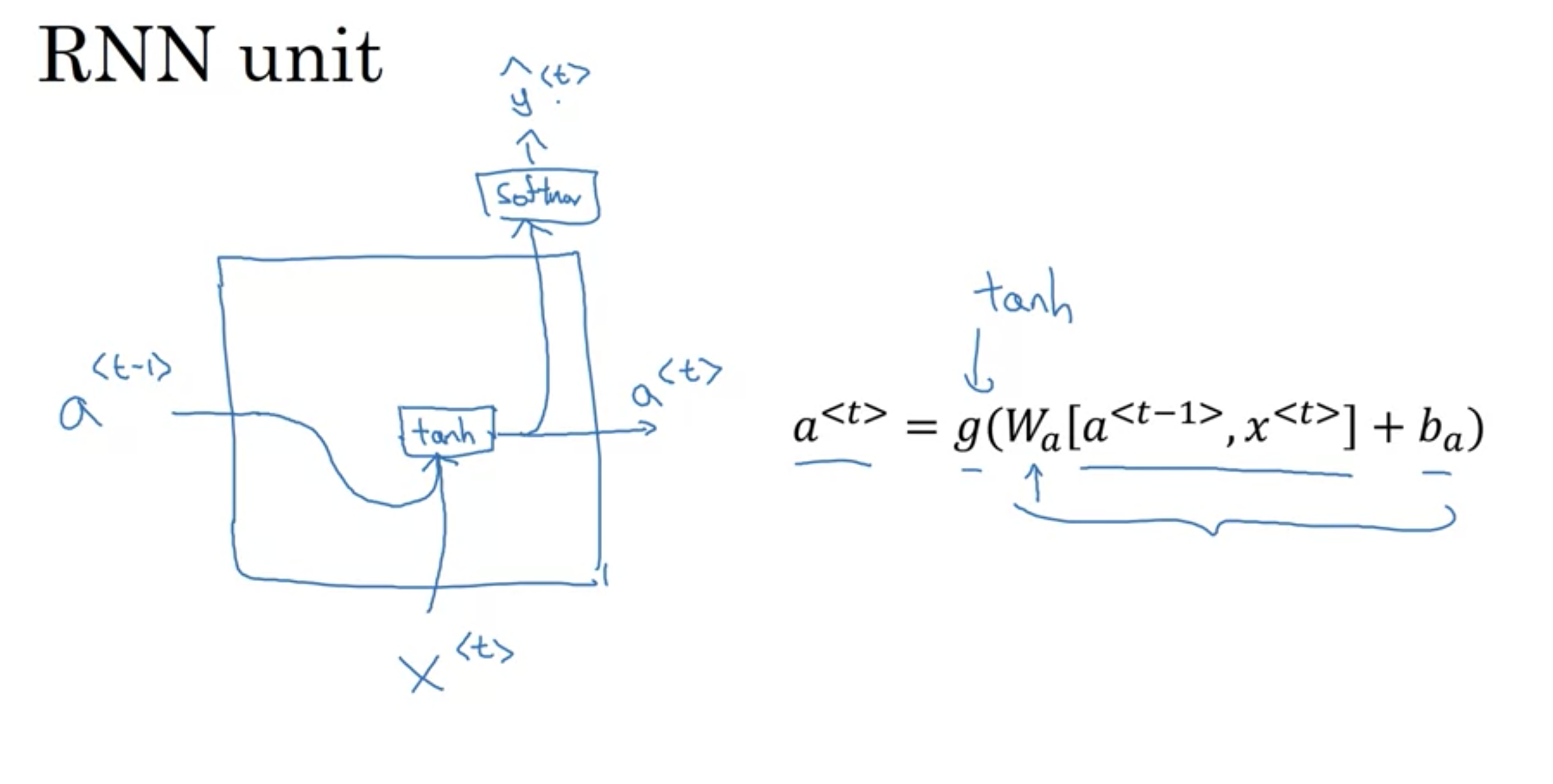 RNN unit
RNN unit
\(\Gamma\) これはガンマと言う記号
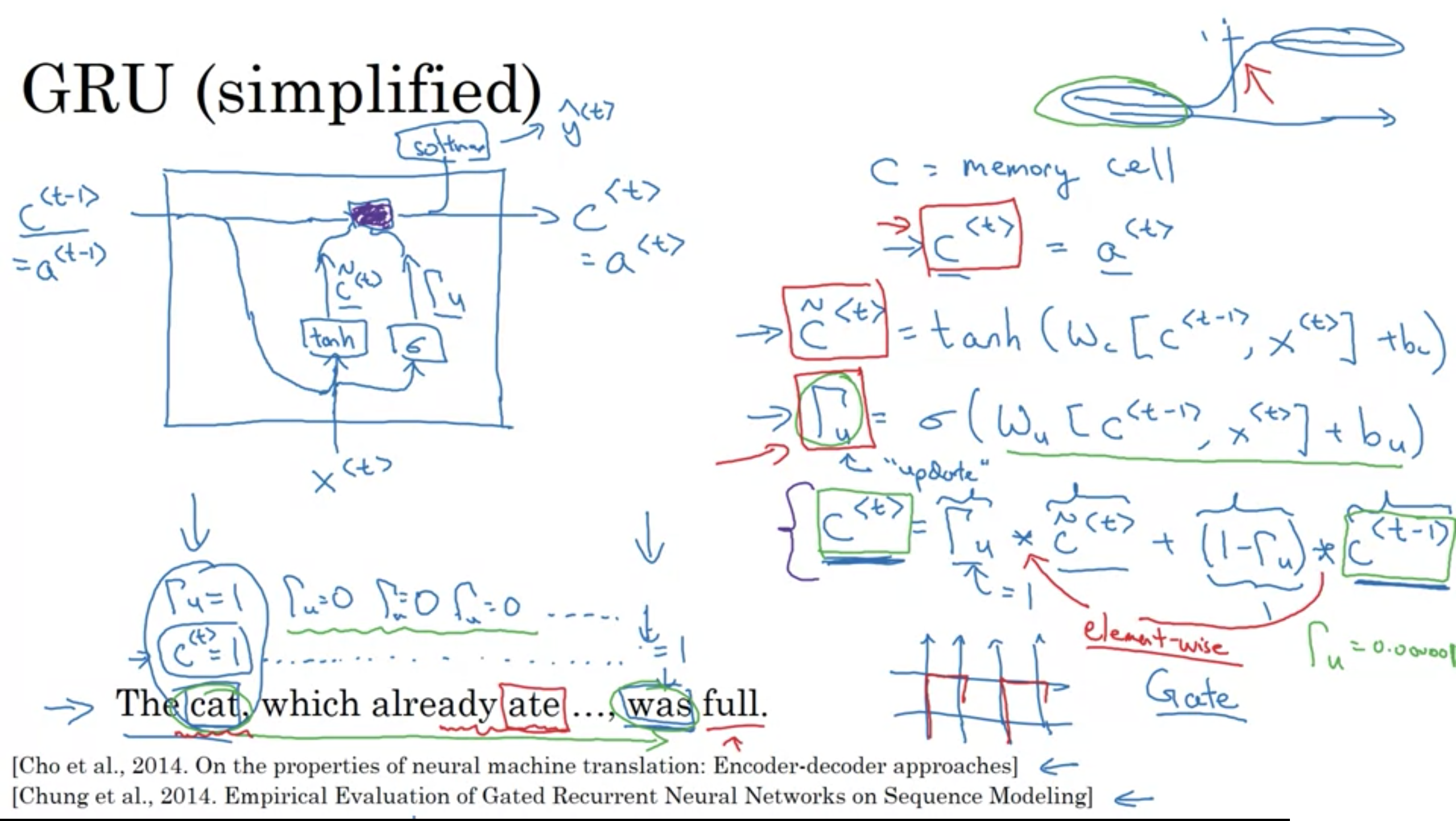
 Full GRU
Full GRU
LSTMは、GRUより少しだけ強力で一般化したバージョン
 GRUとLSTM
GRUとLSTM
論文 Sepp Hochreiter & Schmidhuber 1997 LONG SHORT-TERM MEMORY
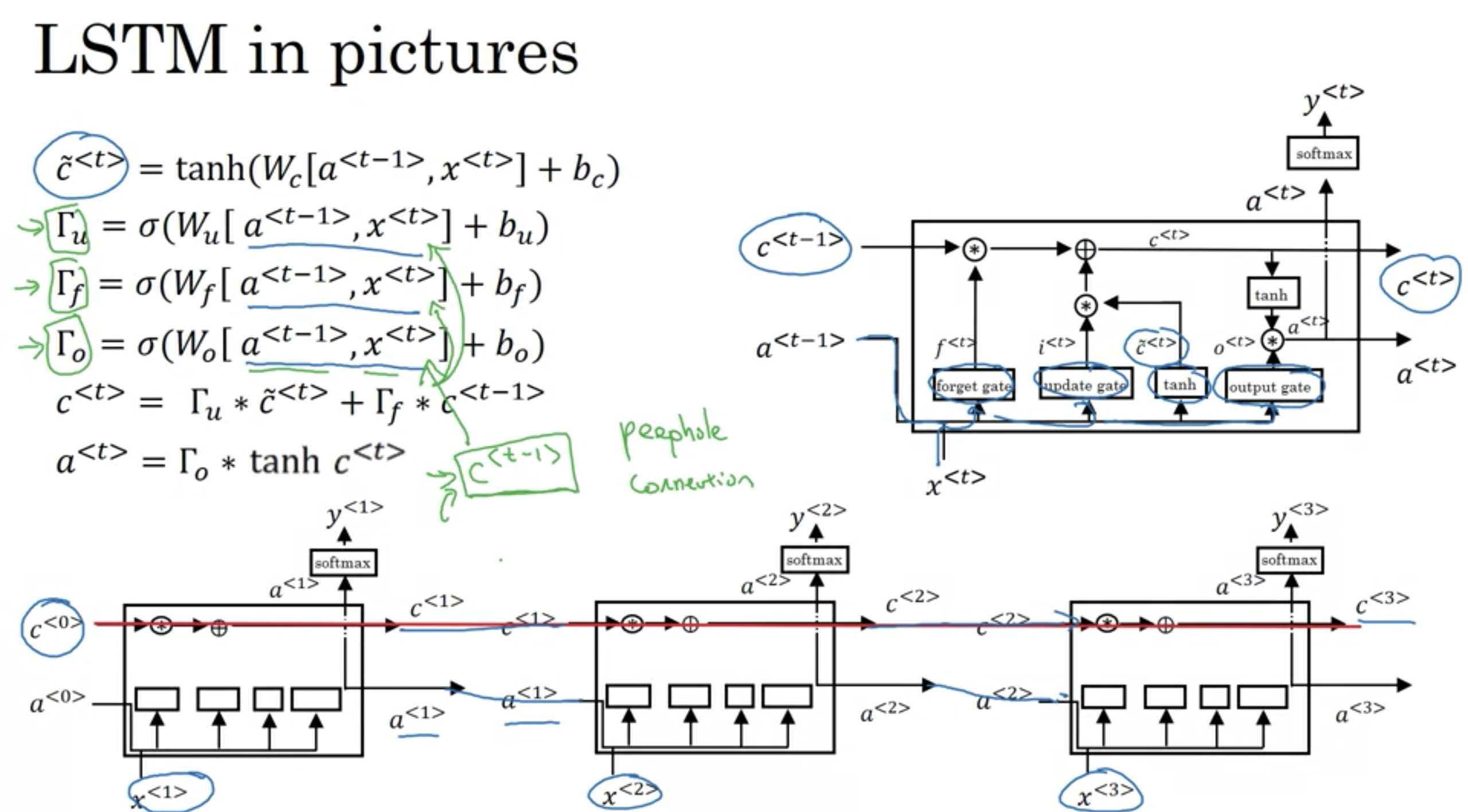 LSTM 画像説明
LSTM 画像説明
分類における予測値にはsoftmaxを使用する
$$\mathbf{y}^{\langle t \rangle}_{pred} = \textrm{softmax}(\mathbf{W}_{y} \mathbf{a}^{\langle t \rangle} + \mathbf{b}_{y})$$
どちらにも利点はあるが、今日ではLSTMを使うことが多い。
GRU
・複雑なLSTMを簡略化したモデルで比較的最近の発明
・モデルの単純であるため、大きなネットワークを構築するのが簡単
・ゲートが2つしかないため、少し計算が高速
LSTM
・GRUよりもずっと以前の発明
・2つではなく3つのゲートがあるため、GRUより強力で効果的
RNNの変種 以下の表は、一般的に使用されている他のRNNアーキテクチャをまとめたもの
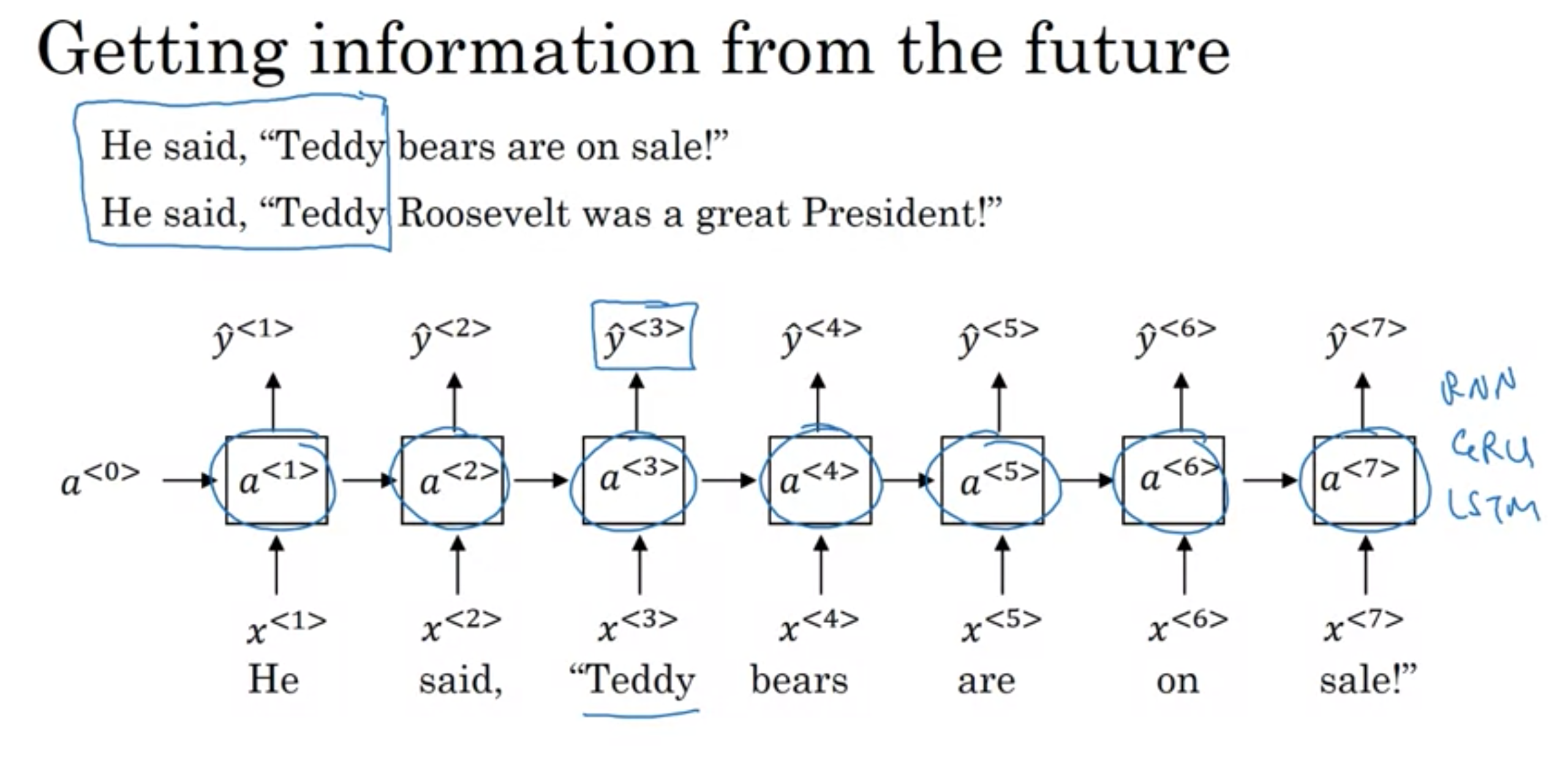 未来の情報の利用
未来の情報の利用
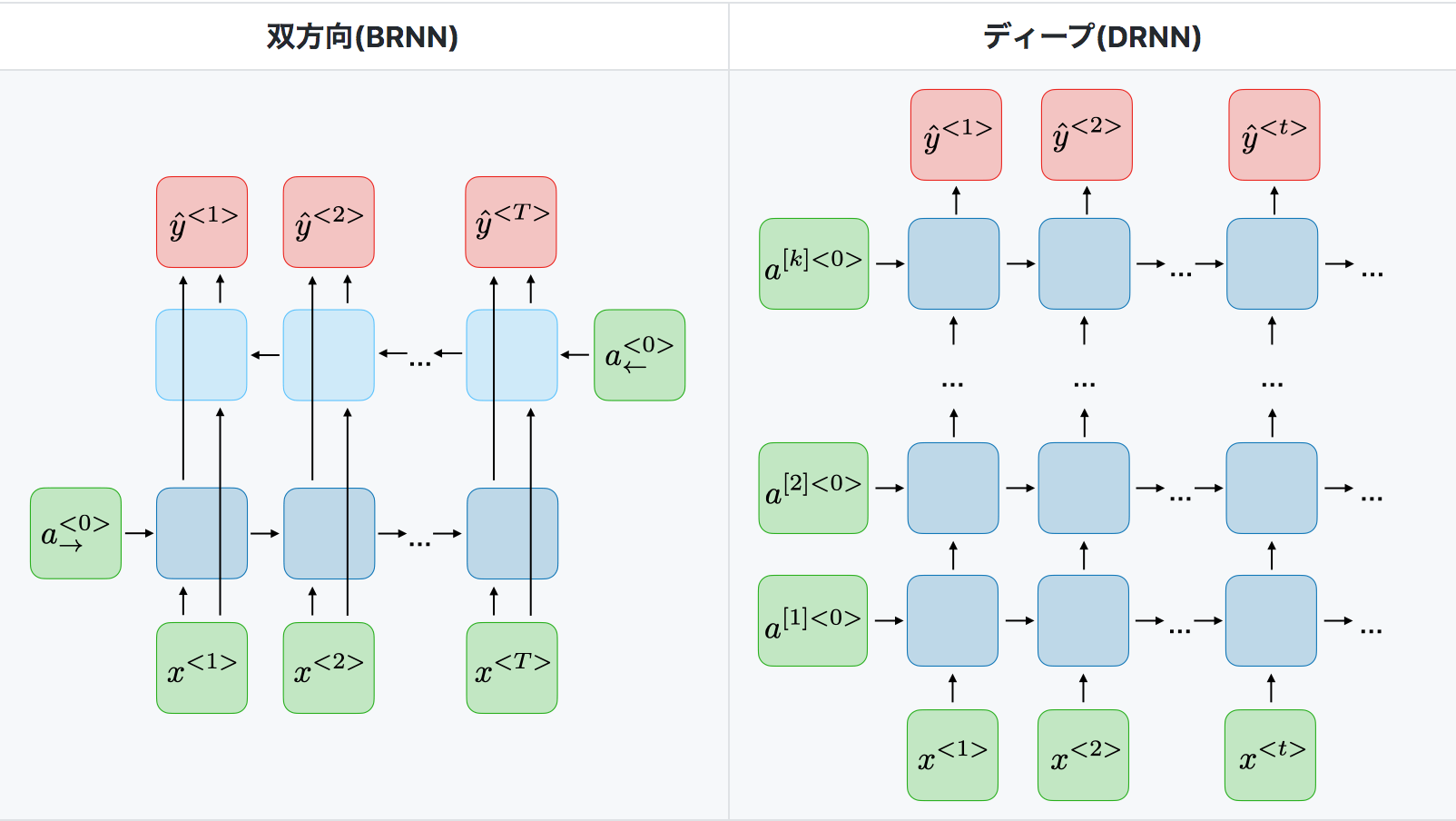
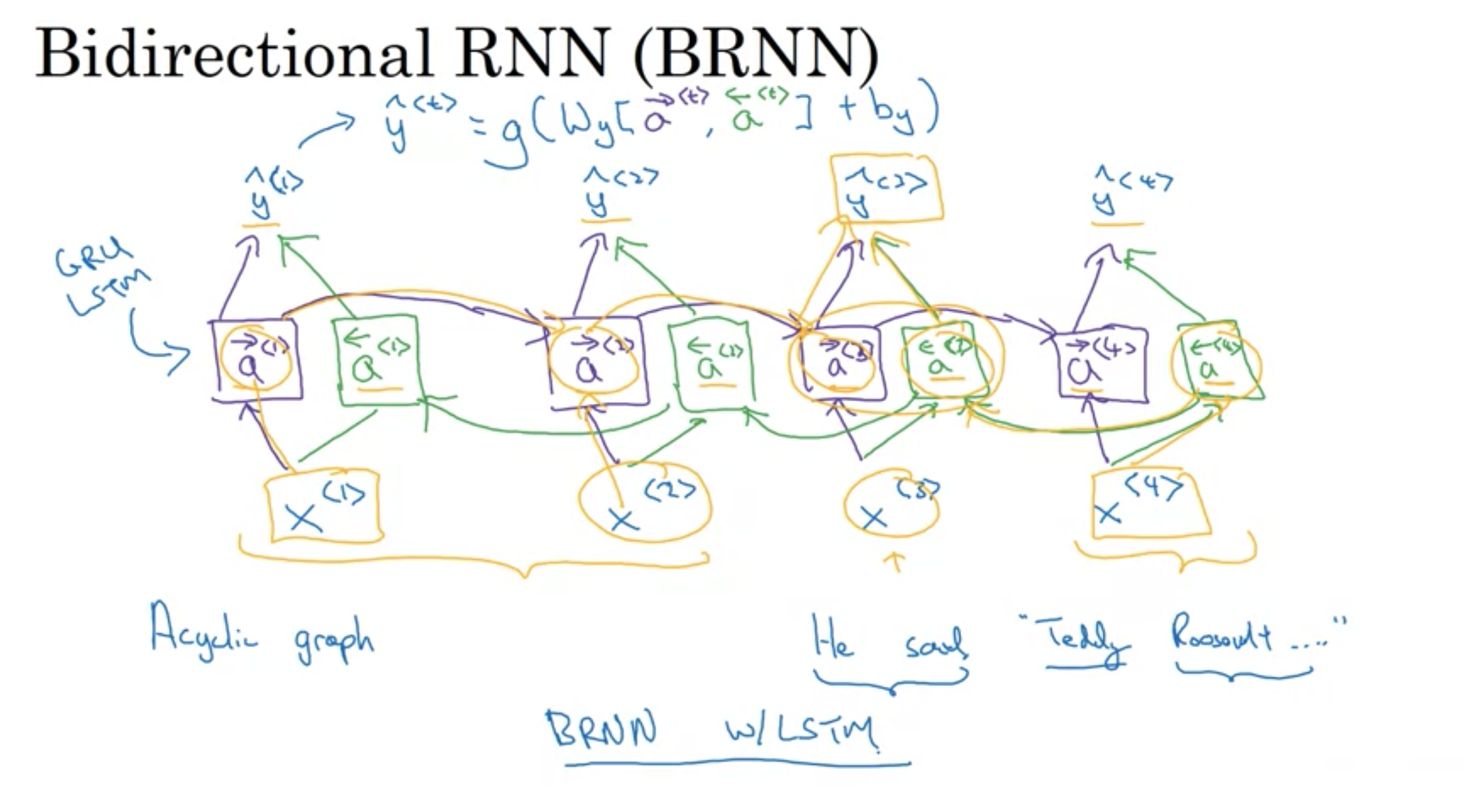 BRNN
BRNN
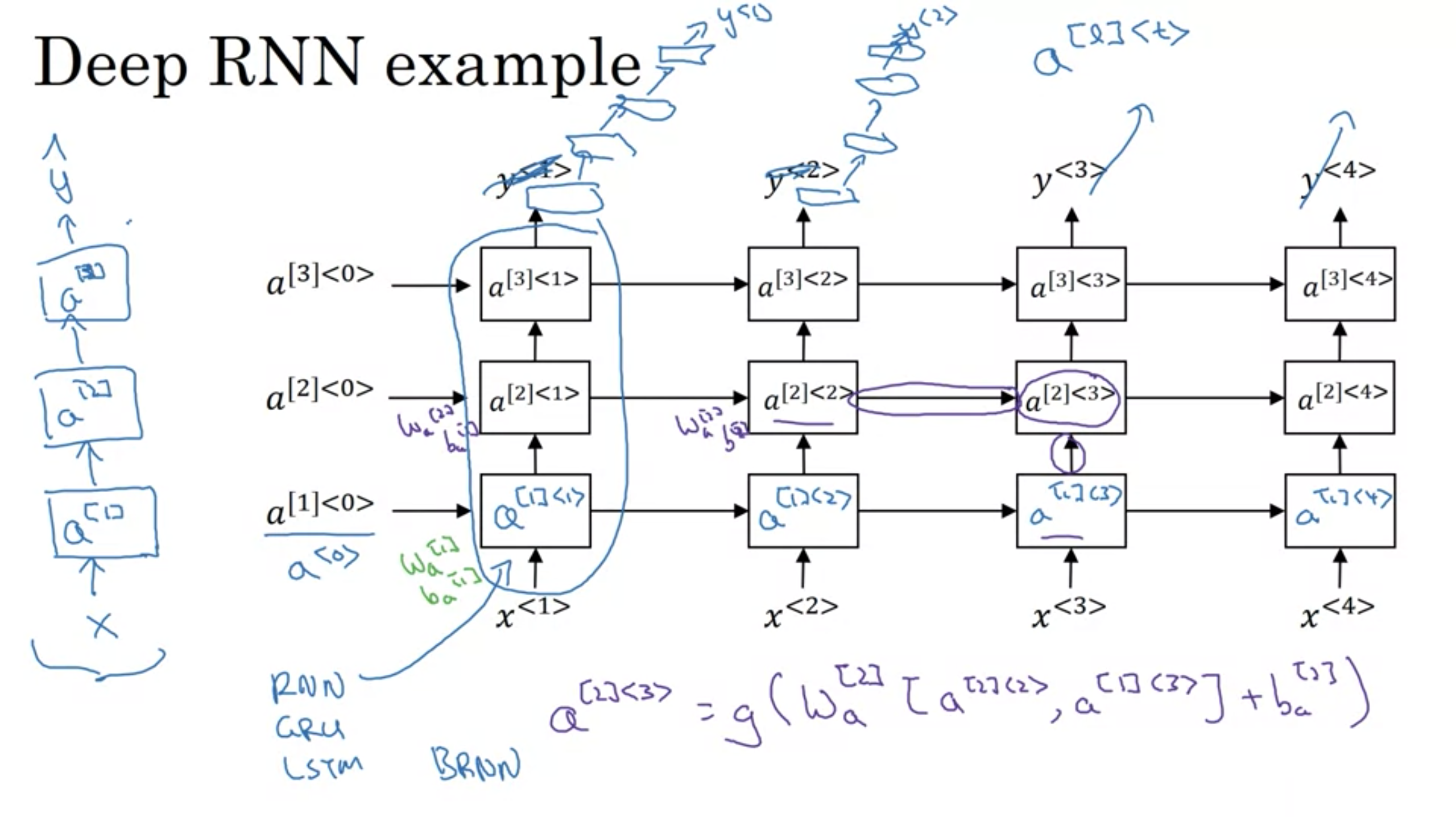 DRNN
DRNN
単語表現
 word representation
word representation

word embeddings
単語埋め込みの可視化
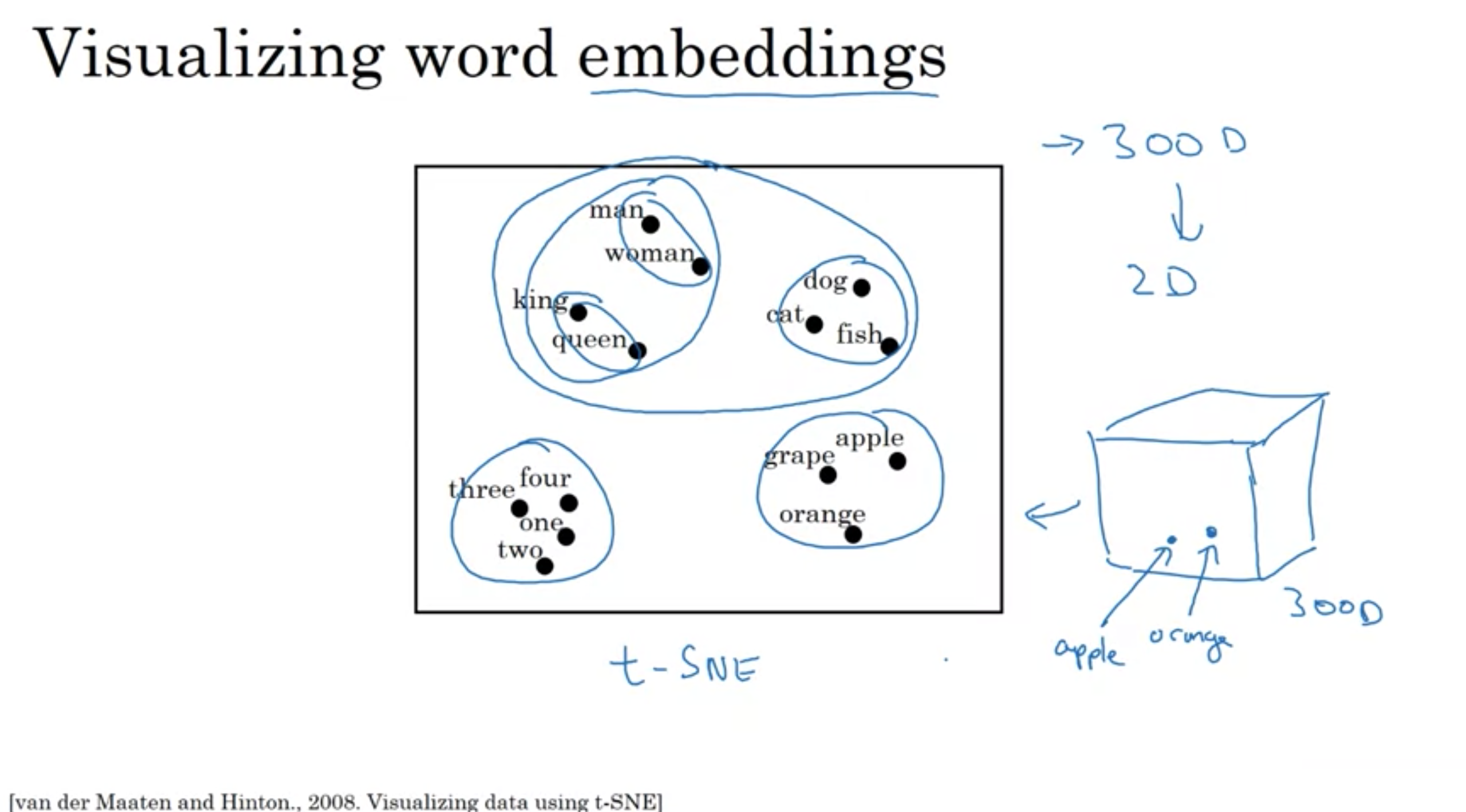 visualizing word embeddings
visualizing word embeddings
名前検出を例
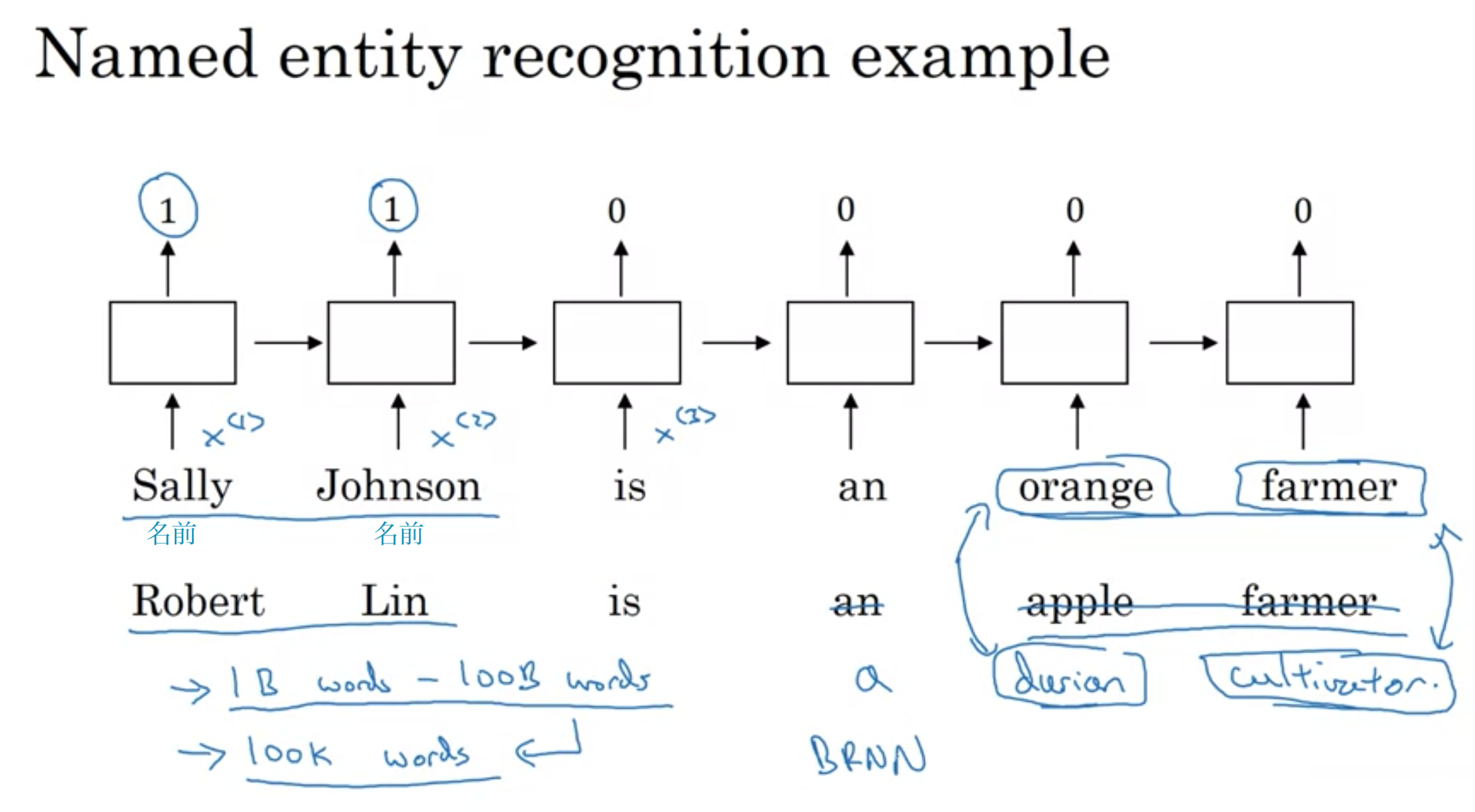 名前エンティティー検出
名前エンティティー検出
 転移学習と単語埋め込み
転移学習と単語埋め込み
単語埋め込みを使用した転移学習
1. 巨大なテキスト群から単語埋め込みを学習(1~1000億)
(または、事前学習された単語埋め込みをオンラインでダウンロード)
2. 学習(またはダウンロード)後に、小さいトレーニングセット(例えば、単語数10万かそれ以下)しかない新しいタスクに転移する
3. 任意: データが十分に多い場合には、単語埋め込みを新しいデータにファインチューニング(パラメータを微調整)すること
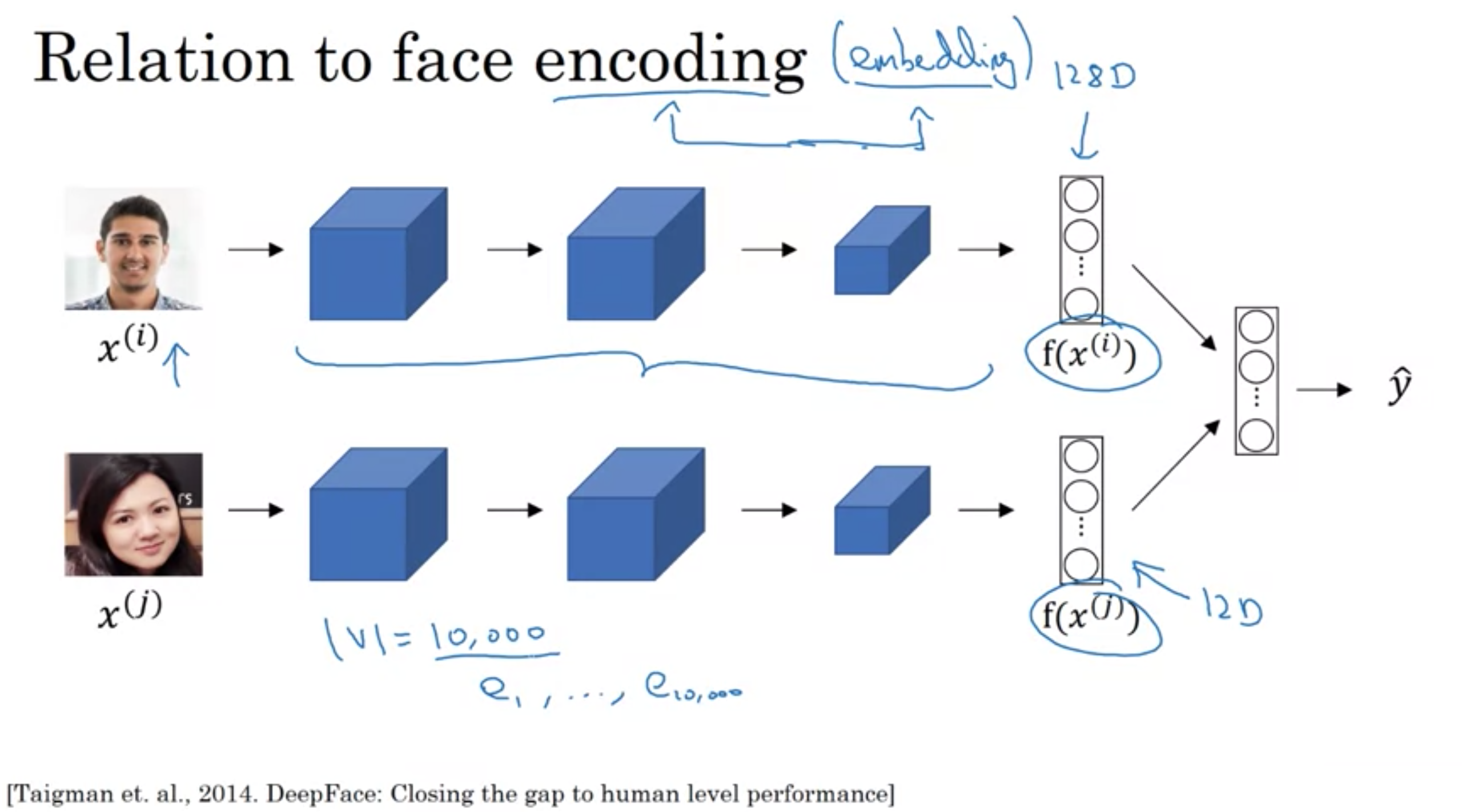
単語埋め込みと、顔認証でのエンコーディングには興味深い関係性がある
・エンコーディングと埋め込みという言葉は多少同じ意味で使用される
・顔認識のために、様々な顔の、例えば128次元表現を学習するシャムネットワークアーキテクチャをトレーニングし、2つの画像が同じであるか判断するために、エンコーディングを比較する
・単語の埋め込みは、例えば1万の固定ボキャブラリを使用し、各単語のベクトルは固定エンコーディングを学習するか固定埋め込みを学習する
顔認識と単語埋め込みで行うことの1つの違い
顔認証は、一度も見たことのない画像を入力にとる可能性があるが、自然言語処理では固定ボキャブラリーを使用するので、未知のボキャブラリーを使用することはない点
男に対応するものが女だった場合、キングに対応するものはクイーンだと人間は思うが、アルゴリズムではどうやって判断すれば良いだろうか?
=> Gender, Royal, Age, Foodなど、項目との関連性を表す単位ベクトルが同じものを見れば良い
以下の結果から男と女の類似度はキングとクインの類似度と等しいことがわかる。
\( \boldsymbol{e_{man}} - \boldsymbol{e_{woman}} \approx \left( \begin{array}{c} -2 \\ 0 \\ 0 \\ 0 \end{array} \right) \)
\( \boldsymbol{e_{king}} - \boldsymbol{e_{?}} = \left( \begin{array}{c} -2 \\ 0 \\ 0 \\ 0 \end{array} \right) \) を満たす\(e_{?}\)を見つける
\( \boldsymbol{e_{king}} - \boldsymbol{e_{queen}} \approx \left( \begin{array}{c} -2 \\ 0 \\ 0 \\ 0 \end{array} \right) \) よりクイーン
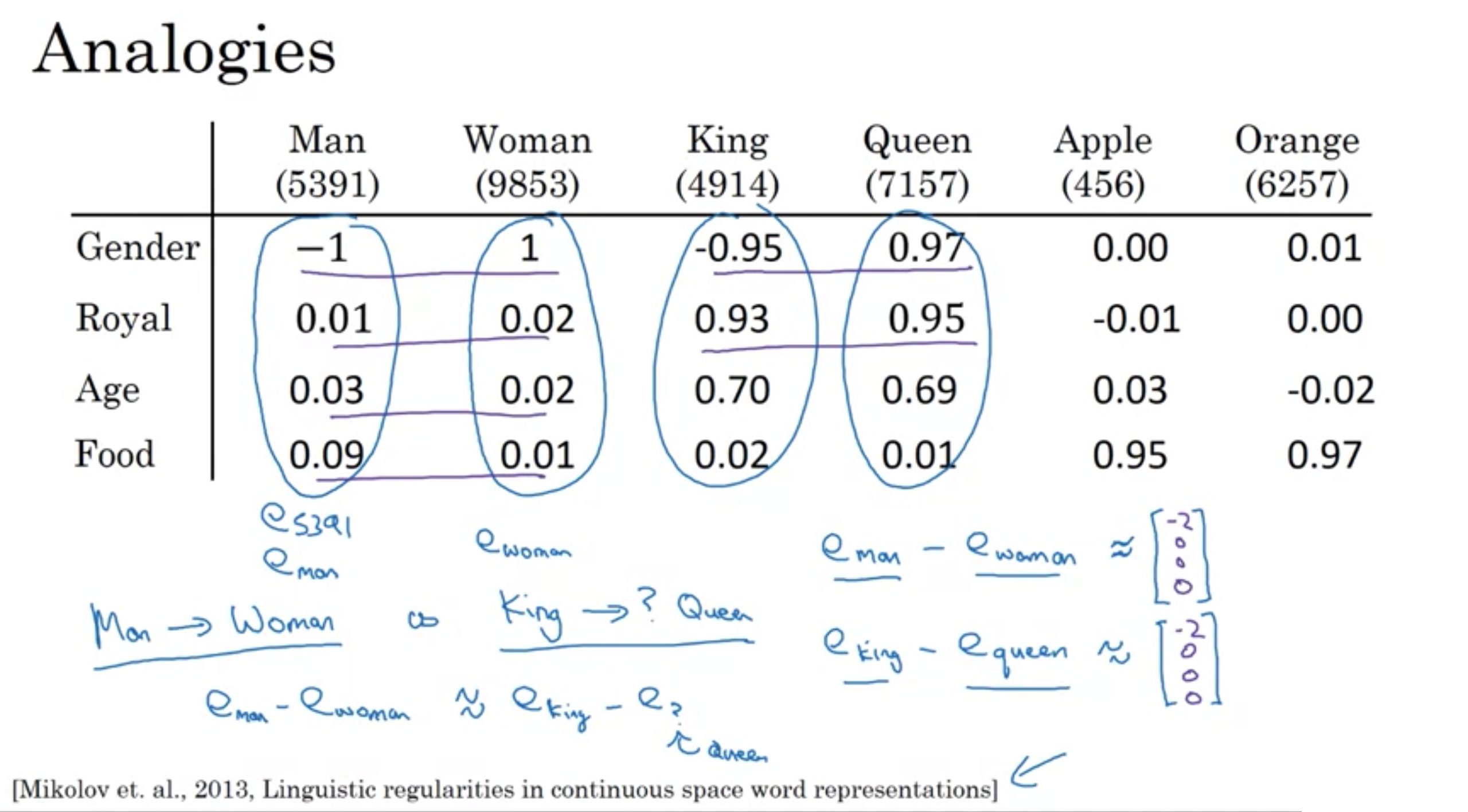 analogy (類似性)
analogy (類似性)
t-SNEは非線形のマッピング
t分布型確率的近傍埋め込み法(T-distributed Stochastic Neighbor Embedding, t-SNE)
・高次元データの可視化のため2次元または3次元の低次元空間へ埋め込みに最適な非線形次元削減手法
最も使用されているsimilarity functionはcosine similarity
ベクトルu, vを用いると、以下で表される。
中学生の時に習う、\( cosθ = \frac{ 内積 }{ ベクトルuの長さ × ベクトルvの長さ } \) と同じです。
\(Sim(u, v) = \dfrac{ u^{ \mathrm{T} } v}{ | \vec{u} | | \vec{v} | } \)
単語埋め込みのアルゴリズム
以下は、ボキャブラリ10,000個の時
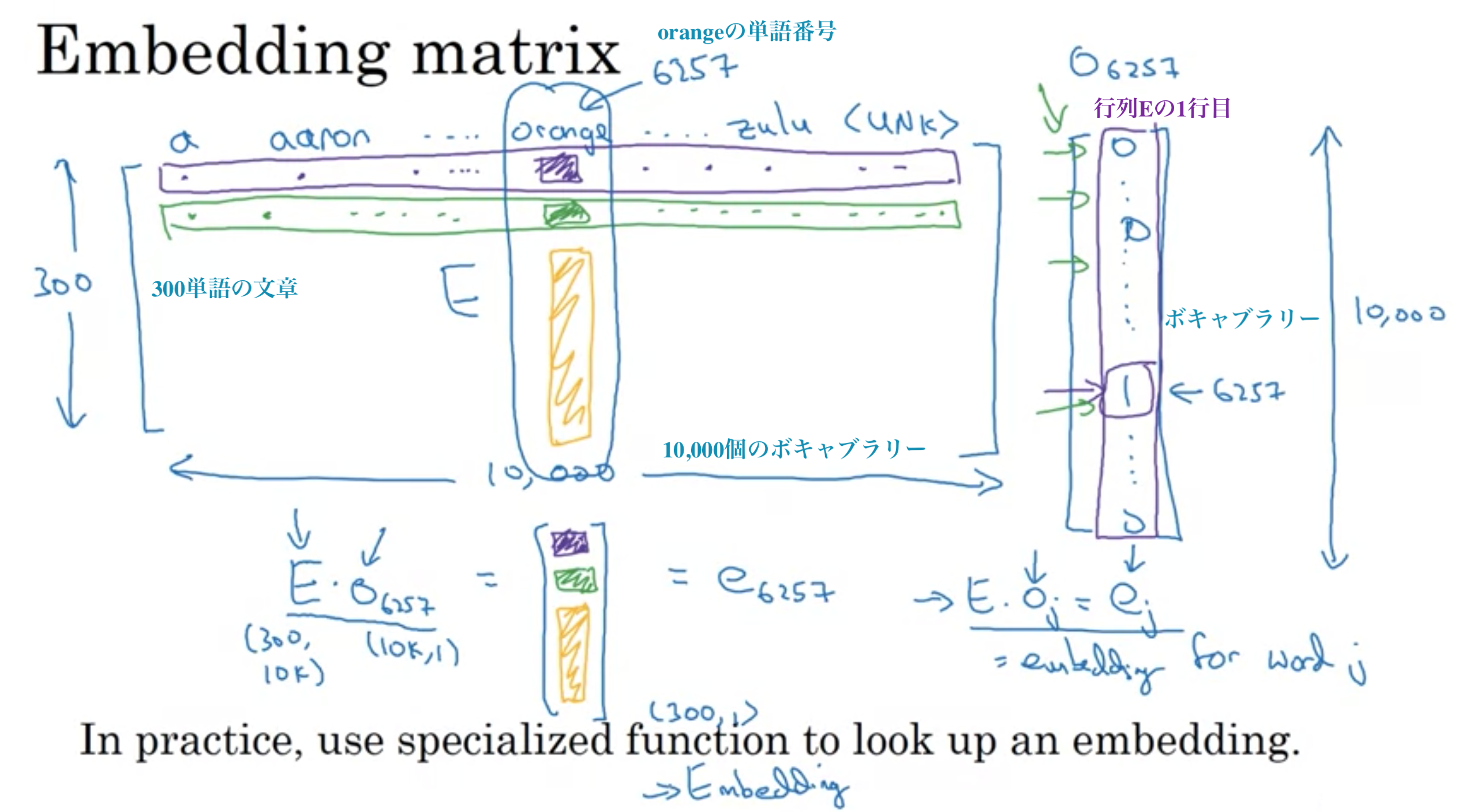 埋め込み行列
埋め込み行列
例えば、前の4つの単語から次の単語の予測を行う場合、a, glass, of, orangeの4ベクトル(300行のベクトル)が入力になる
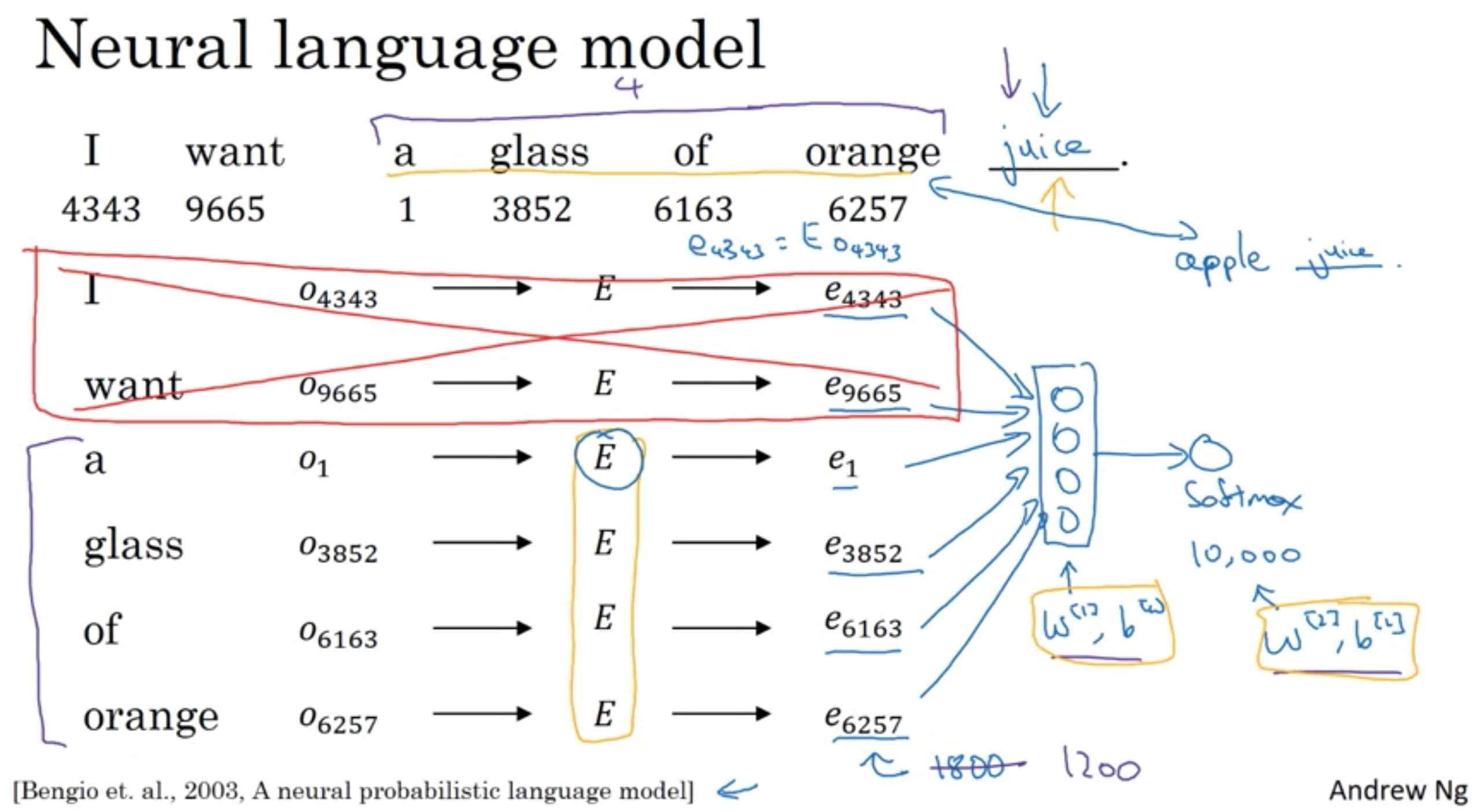
その他(上記のような直前の4単語以外)のコンテキスト/ターゲットのペア
コンテキスト(予測に使う入力)とターゲット(予測する単語)
左右の4単語 a glass of orange juice ? to go along with
直前の1単語 orange ?
近くの1単語 glass ? (スキップグラム)
 コンテキストとターゲットのペア
コンテキストとターゲットのペア
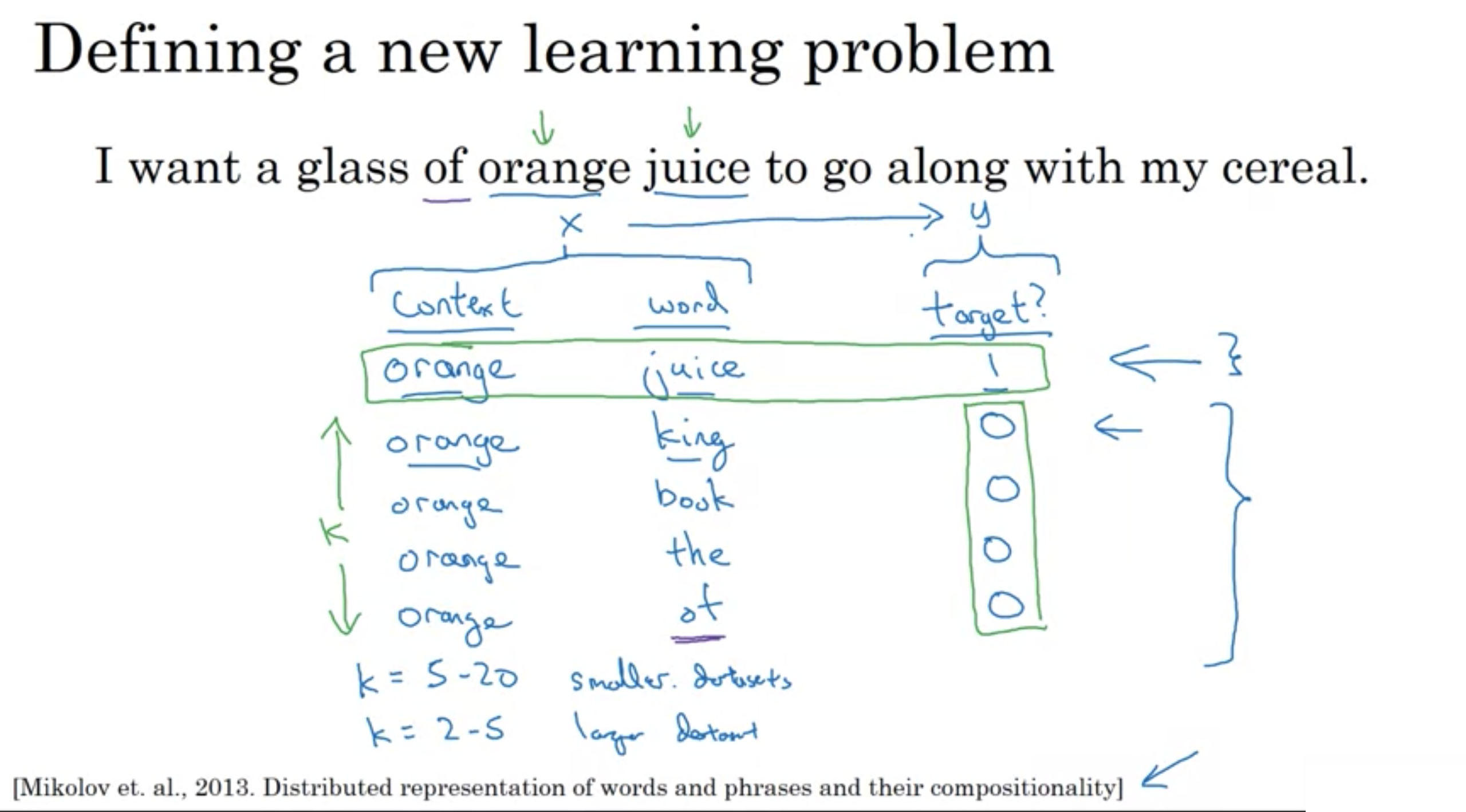
スキップグラム
コンテキストを常にターゲット単語の直前の最後の4単語または最後の直前単語にするのではなく、たとえば、コンテキスト単語としてランダムに単語を選択します。そして、オレンジという言葉を選んだとしましょう。
次にウィンドウ内(コンテキスト単語から例えば、前後5単語もしくは10単語の範囲)で別の単語をターゲット単語として選択する。
ターゲット単語にmyという単語が選ばれたとすると、ウィンドウ内の単語は非常に多様でありうるため、これを教師あり学習で学習するのは困難です。
適切な単語の埋め込みを学習して、予測を行うモデルを紹介する
 スキップグラム
スキップグラム
コンテキスト単語からターゲット単語のマッピングを学習する教師あり学習を訓練
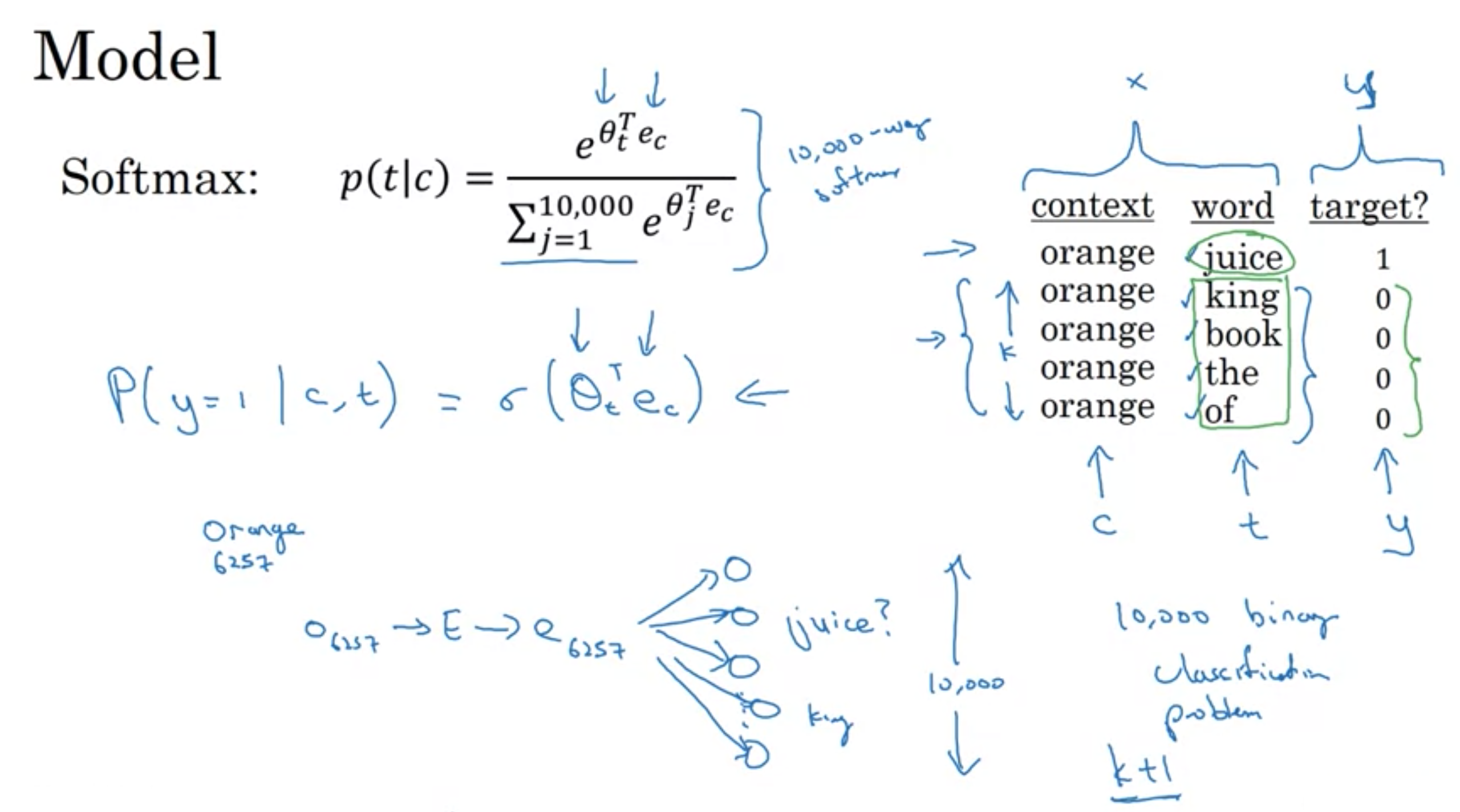
θt: 出力tと関連づけられたパラメータ
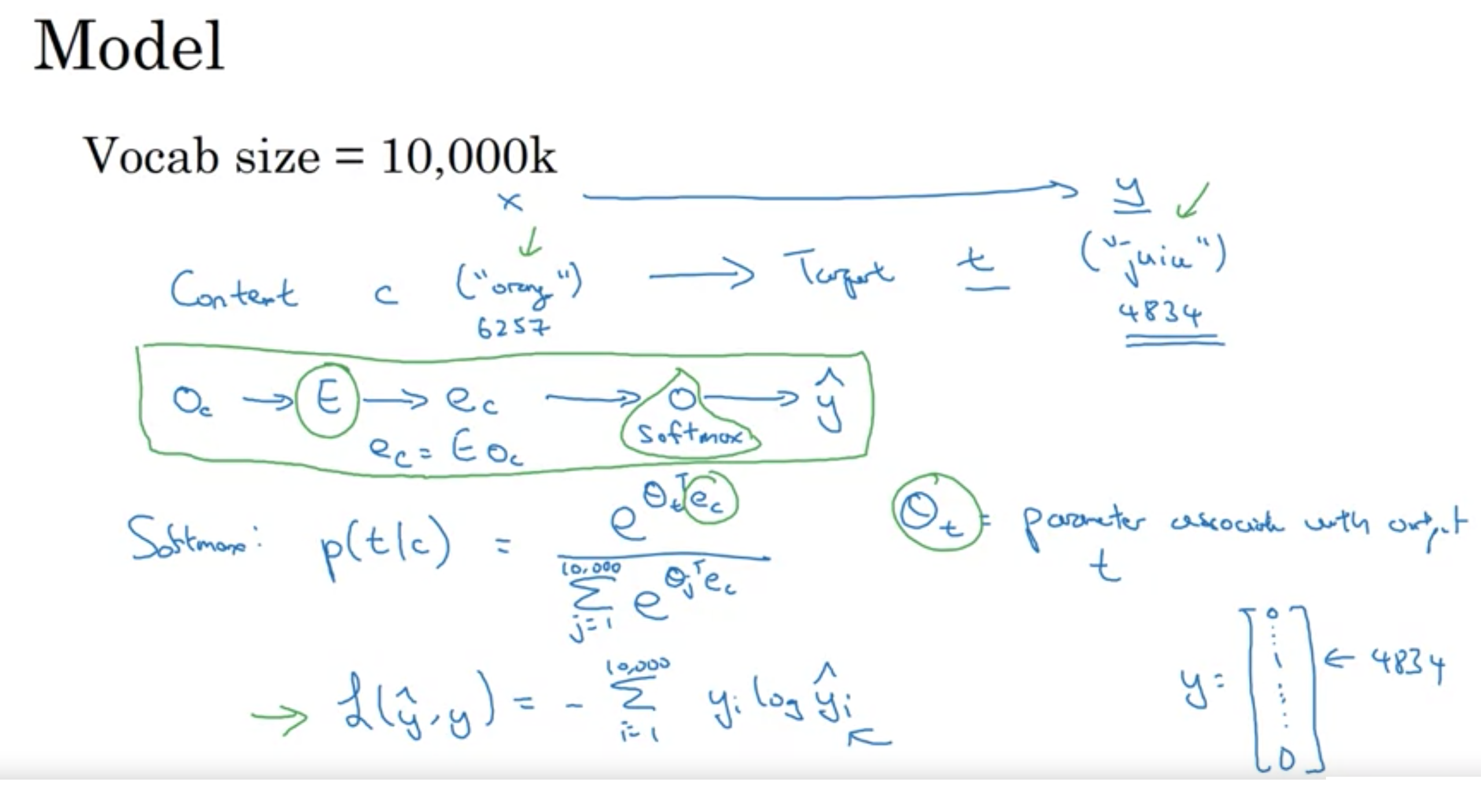 コンテキストとターゲット モデル
コンテキストとターゲット モデル
word2vecのCBOWモデルとskip-gramモデルで、階層的なソフトマックスが頻度の低い単語に対して優れているのに対し、ネガティブサンプリングが頻繁な単語に対して優れている
・スキップグラムの主な問題は計算速度 (シグマによる部分和により、ボキャブラリの数だけ加算を行わなければならない)
・ボキャブラリが1万の場合はそれほど問題ないが、10万~100万になると速度がとても遅くなる


GloVe (Global vectors for word representaion) 単語表現のためのグローバルベクトル
Word2Vecやスキップグラムモデルほど使用されていないが、単純性の点から、一部の愛好家がいる。
Xijはコンテキストiの中に単語jが現れる回数
iとjはtとcに成り代わっている
コンテキストと単語の定義をプラスマイナス10単語ないに同時出現するかどうかという定義にすれば対称な関係性になるXij=Xji
コンテキスト単語を必ずターゲット単語の直前と定義すると対称にはならない
 GloVe
GloVe
参考文献 GloVe: Global Vectors for Word Representation
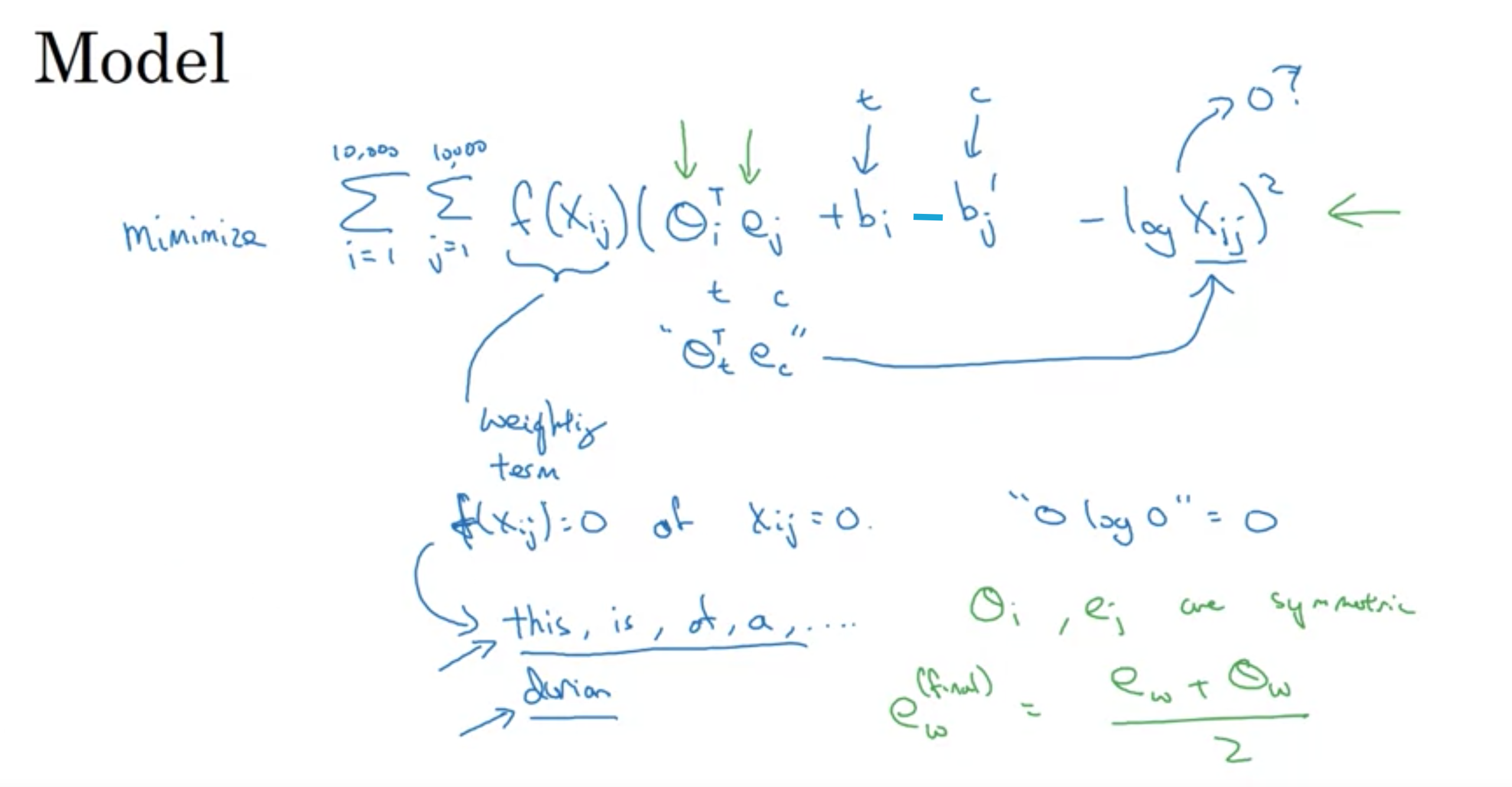 GloVe モデル
GloVe モデル
 単語埋め込み
単語埋め込み

シンプルな単語埋め込みモデル
以下の分では、実際は非常に過酷なレビューであるにも関わらず(文中のgoodにより)良いレビューと分析してしまう
"Completely lacking of good taste, good service, and good ambience."
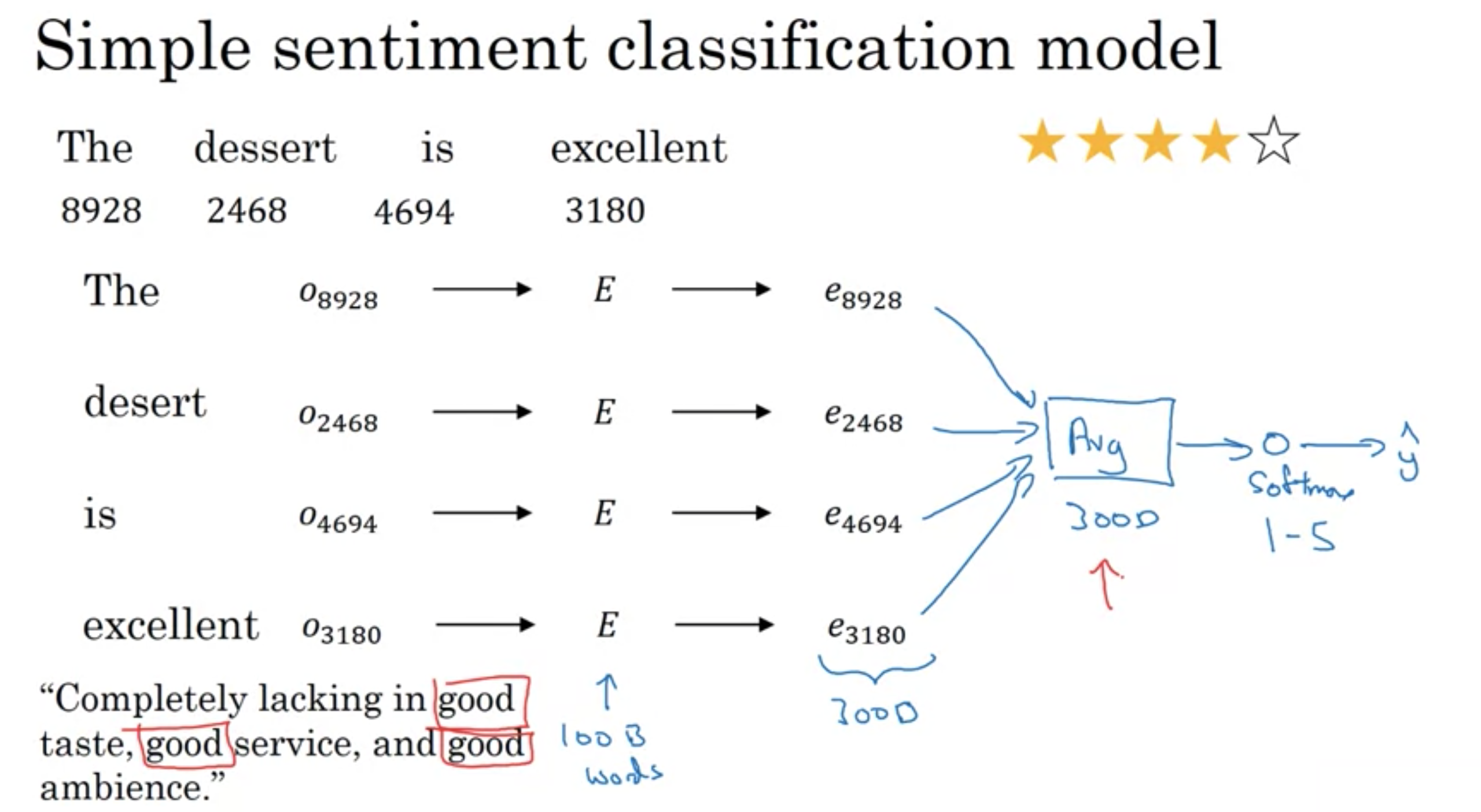 シンプルな感情分析モデル
シンプルな感情分析モデル
単に、単語ベクトルを足し合わるのではなく、RNNモデルを使用することもできる
RNNの構造 many to one (入力多から出力1を意味する)
前のモデルとは異なり、RNNでは単語の順序を考慮に入れるため、"lack"や"absense"などのネガティブな文脈を認識して分析できるようになる
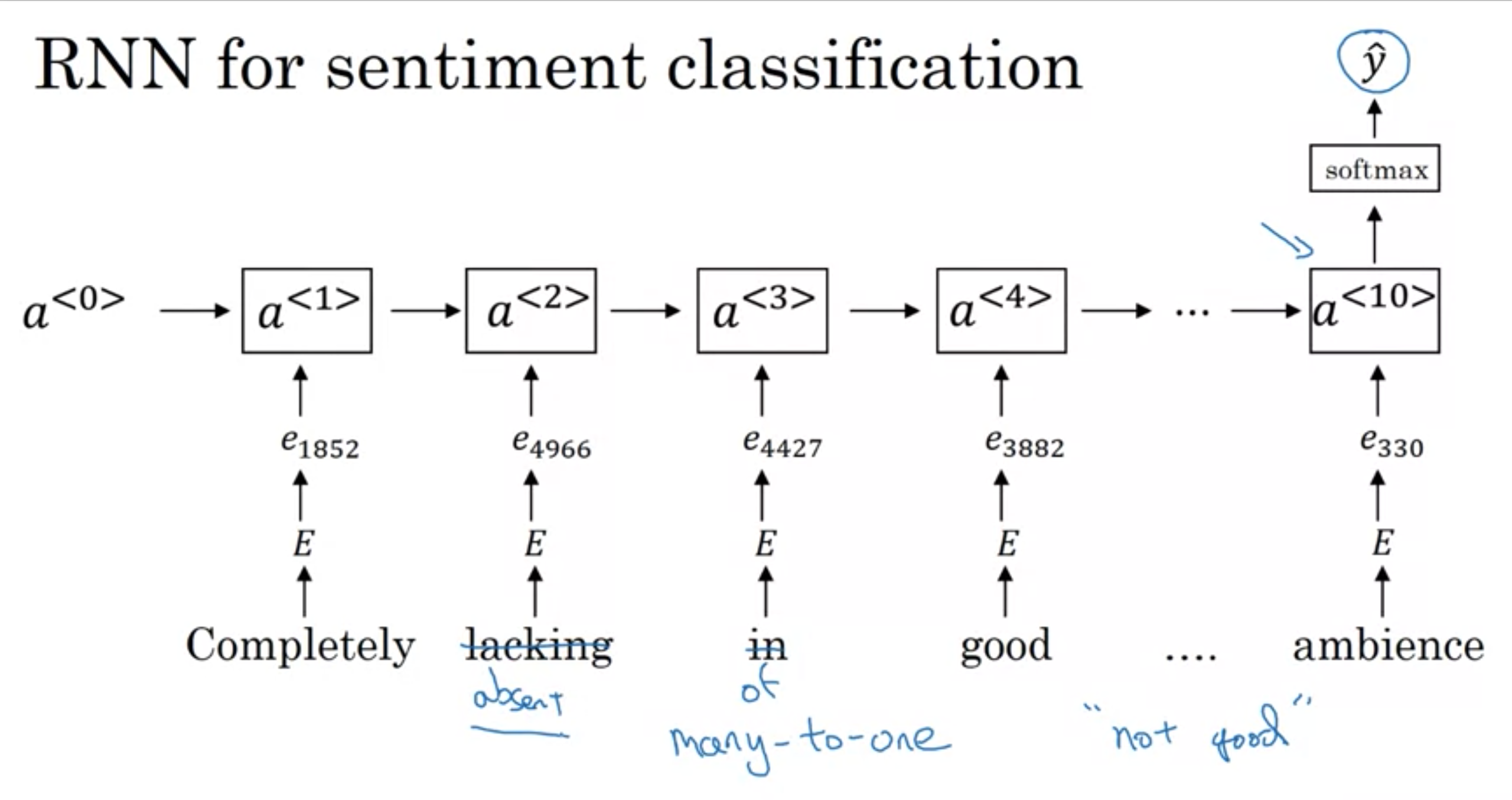 RNNでの感情分析
RNNでの感情分析
ここでのバイアスは、統計学でのバイアスではなく、偏向を意味する
単語の埋め込みにおけるこれらの形式のバイアスを軽減または排除するためのアイデアのいくつかを示す
「男性がコンピュータプログラマーだったら、女性は主婦」「父が医者だったら母が看護師」みたいに、偏った見方をあまり持つべきではない。
特に注意すべきが、社会経済的地位に関連するバイアスです。 裕福な家庭でも、低所得の家庭でも、その間のどこからでも、誰もが素晴らしい機会を持つべきだと思います。
 単語埋め込みによる偏見問題
単語埋め込みによる偏見問題
参考文献 Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings

シーケンスデータの入力からシーケンスデータの出力を行うモデル
入力: <x1> <x2> <x3> <x4> <x5>
Jane visite l'Africa en September
出力: <x1> <x2> <x3> <x4> <x5> <x6>
Jane is visiting Africa in September
訓練方法
- エンコーダーネットワークをRNNで構築 (GRUや LSTMでも可能)
スキップグラム 参考記事
https://www.randpy.tokyo/entry/word2vec_skip_gram_model
個人的に好きなRNNチートシート
https://stanford.edu/~shervine/l/ja/teaching/cs-230/cheatsheet-recurrent-neural-networks